Hello,
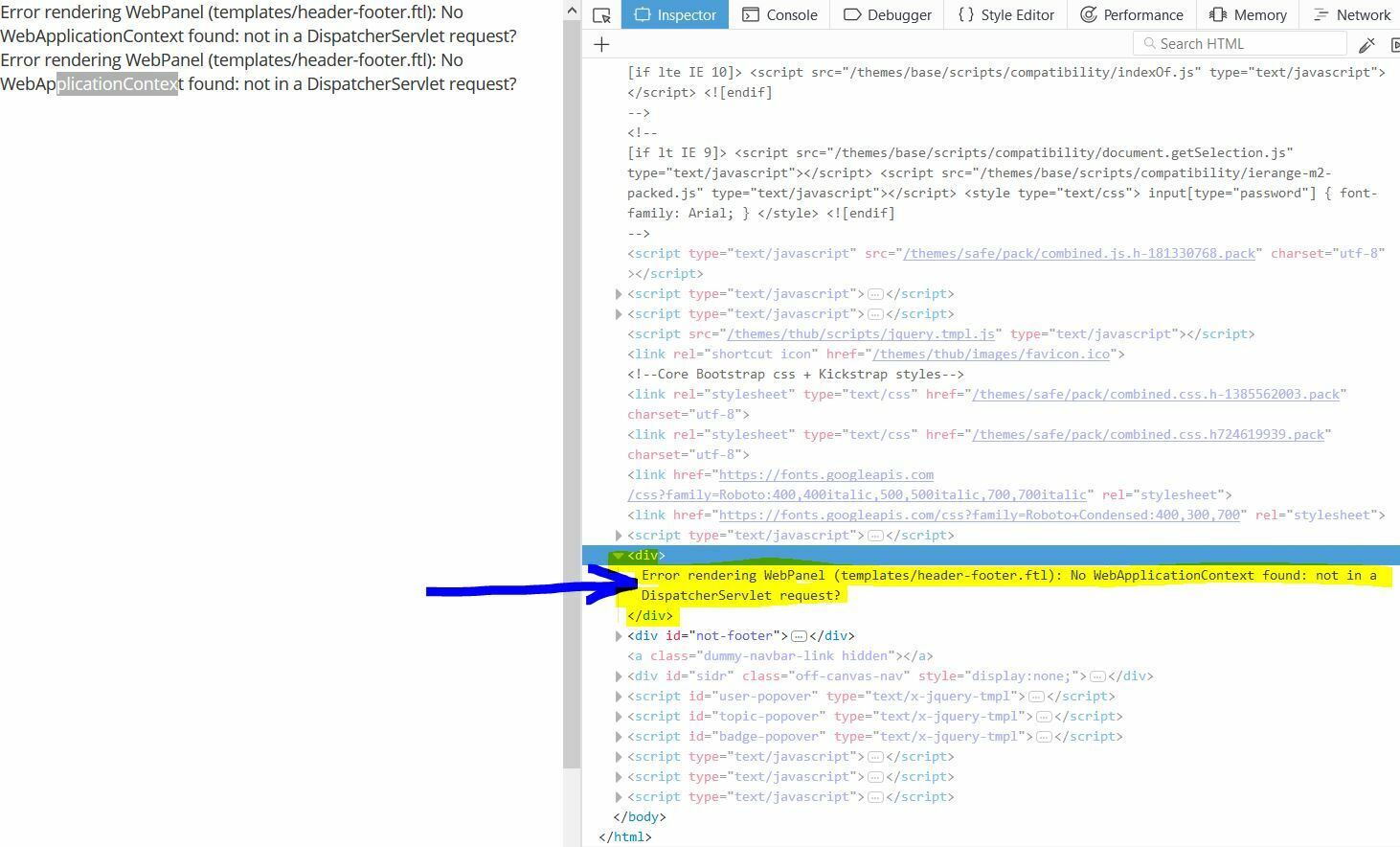
I am trying to parse an HTML page with FME 2014 but, after a bunch of tests, I do not succeed in decoding the rather simple <table> section of my HTML imput. I fear that my troubles come from the FME version I am currently using.
I have indeed read many posts dealing with HTMLExtractor, HTML Table Reader but these transformers are only available in 2017 version (thanks to @takashi for all of them !).
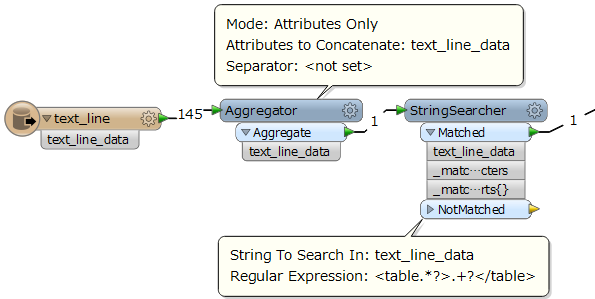
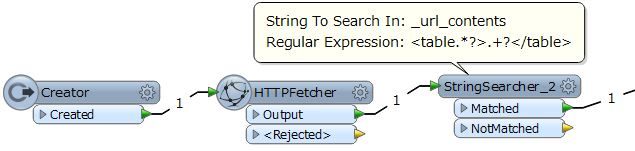
Can someone tell me if there is a way to decode HTML table section with 2014 version of FME and how ? I join a sample of the file I have been trying to decode (the <table> part is the only interesting section of this file).
Any help would be really appreciated.
Thanks a lot.