
Hi everyone,
I have a feature class in a File Geodatabase that I need to update. I have two sources for these updates: a CSV file with codes of the changed features, which I should use to remove those features from the main dataset, and separate shapefiles for each changed feature that needs to be added back to the main dataset. (I shouldn’t delete and update the whole dataset, I should update the changed features only.)
What is the best way to approach this in FME?
Thank u in advance for your time.

Solved
How to update a dataset using a change table in FME

 +7
+7- Contributor
Best answer by jobvdnoort
If I understand correctly, your dataset consists of a folder containing a number of shapefiles, with each shapefile defining a specific feature.
Additionally, there is a separate CSV file that contains the changes to be made to the main geodatabase.
These changes should also be applied to the source shapefiles in the folder.
To achieve this, you can follow a few steps:
Use the FeatureReader to read all the .shp files in your directory.
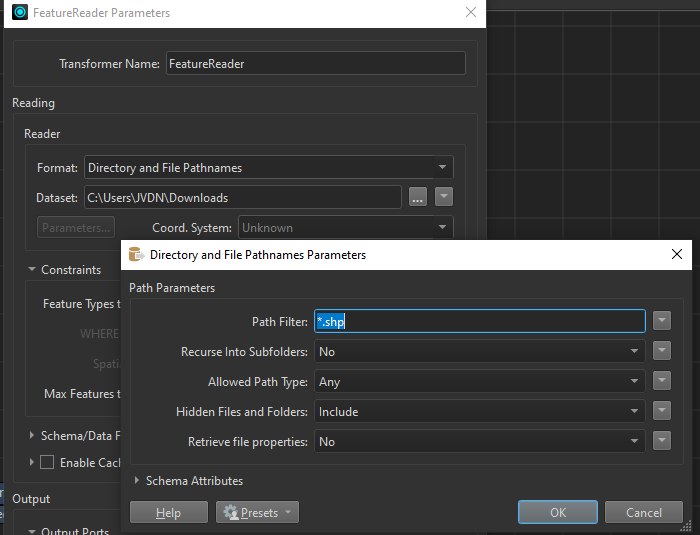
Read the CSV file to understand the changes that need to be applied.
Use a FeatureMerger to update the geometry and attributes of the shapefiles based on the CSV data.
And last
Overwrite the shapefiles and write the updated data to the geodatabase.
Hope this helps? If I understood wrong, could you provide me with some example?
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.



Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.