
I am a new FME user and am trying to extract a text information from a PDF. Reading this fórum I came up with this:
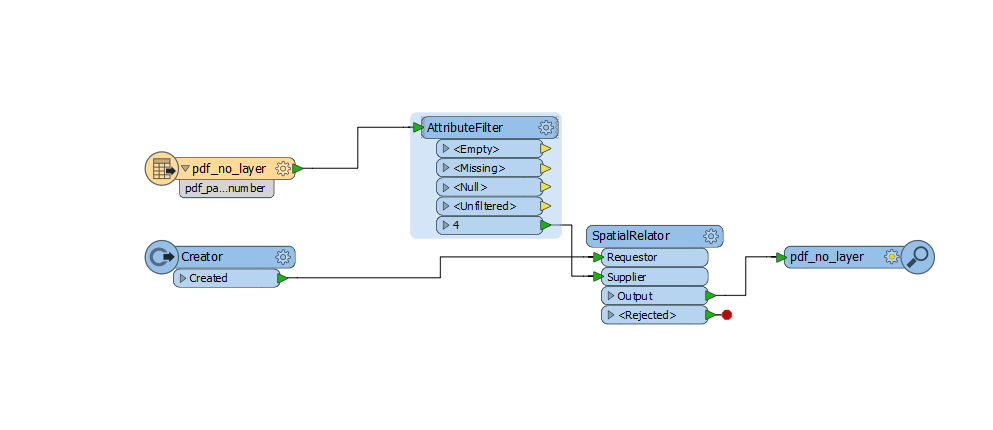
Using attribute filter I choose the page number I need to extract that information and the inspector showed me this:
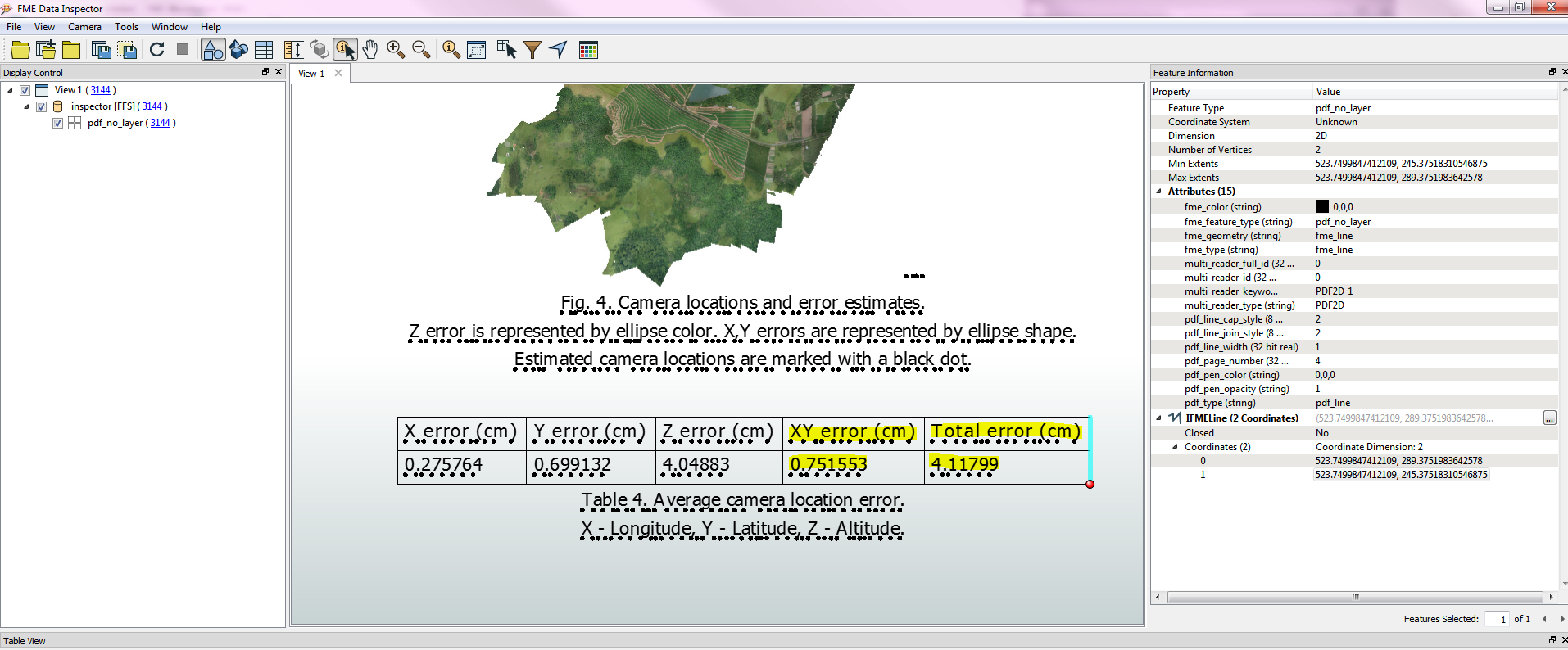
The yellow text is the information I need to extract. How do I do extract that to a excel file or csv?






