Hi all, i know it will maybe an easy one….I’ve tried with substringextractor or with AttributeTrimmer as well but i couldnt reach the right result.
i have attribute like these for example:
he0_wasser_WSG_TK_20143_AGE_f_r01_231030 or ni0_geobasisdaten_gemischte_industrie_gewerbe_flaechen_20256_AGE_f_r01_240118
i have to split in this case “he0” and “ni0” and write that in an attribute x i have to split “wasser” and “geobasisdaten” and write that in an attribute y
i have to split “AGE” in an attribute…….and so on
now comes the challenge: the text between “wasser” or “geobasidaten” and the 5digit number (20143, 20256) has sometimes 2 words, sometimes 3 or 5 words…..but i have to write the whole text in an attribute z….ho can i do that?
i am not so well in regexp…..so i ask here for help
Thank you
Cheers
Franco
Best answer by franco69
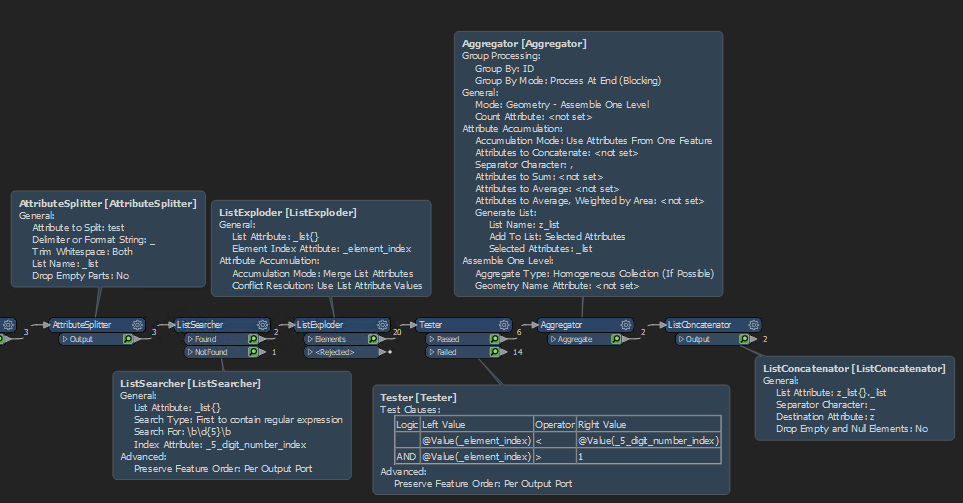
I would avoid intricate RegEx expressions. They are hard to debug and they do not work the same in every environment.
I have solved this using the following native tools:
AttributeSplitter splits attribute and puts every part between the underscores in a list item.
ListSearcher searches the list using RegEx for 5 digits and returns 5_digit_number_index.
ListExploder explodes list.
Tester filters out the first two elements (index 0 and 1) and all the elements that share the same index or higher as the 5_digit_number_index.
Aggregator (grouped by ID) aggregates all list features together and creates a new list (Generate List: z_list).
Finally the ListConcatenator creates the output string of all string elements between the first two elements and the 5 digit number.
That do the work for me….thank you….but the listconcatenator is not necessary because to concatenate the attributes inside the aggregator also do the work
thx a lot and cheers
Franco
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
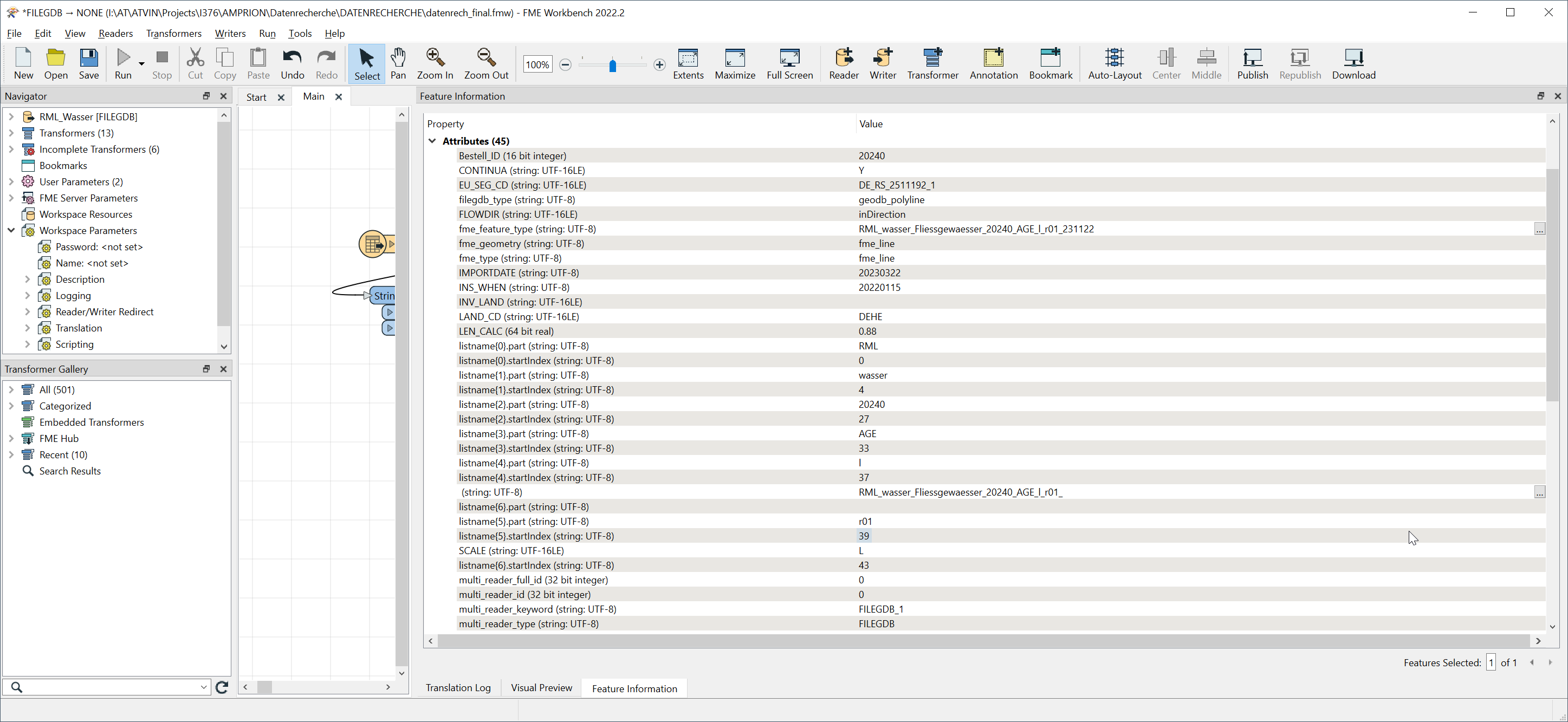
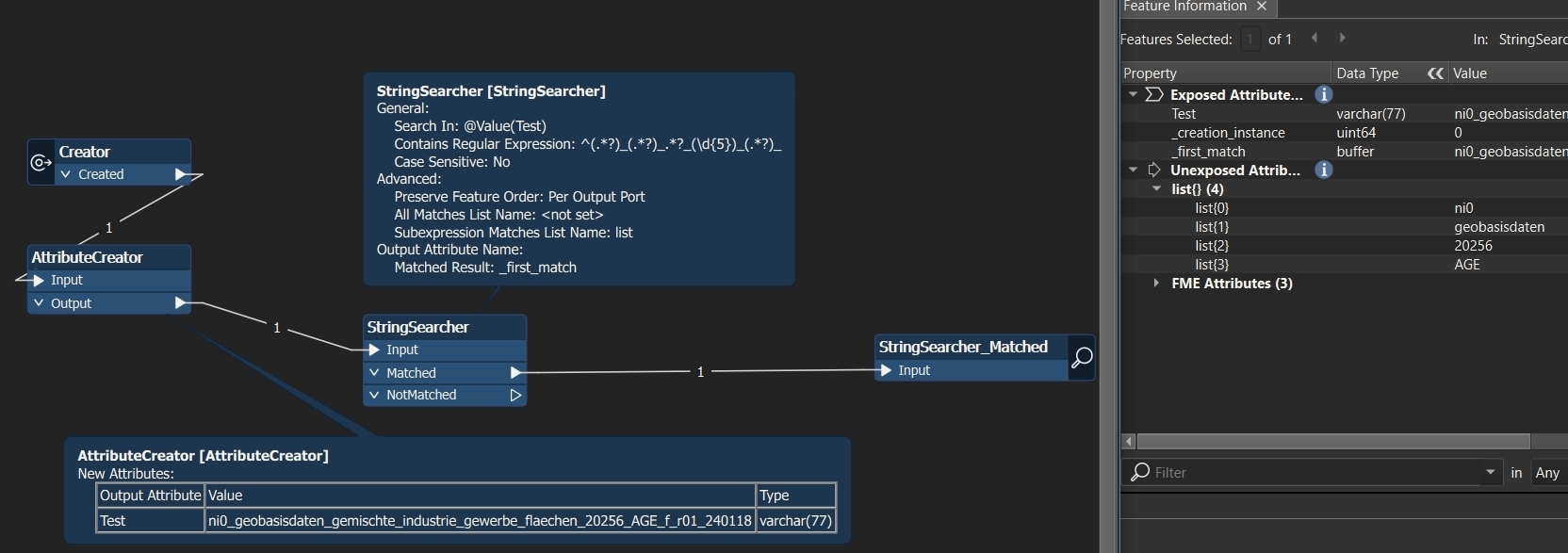
hmmm…..list was created but not right…….. fme_feature_type is the attribute to split
listname 0 is ok listname 1 also ok listname 2 should be Fliessgewaesser……….here in this case is only one word between second underscore and the 5 digit number (but there could also be 3 or 4 words)
listname 3 should be 20240 (is now listname 3) listname 4 should be AGE (is now listname 4) and so on
I would avoid intricate RegEx expressions. They are hard to debug and they do not work the same in every environment.
I have solved this using the following native tools:
AttributeSplitter splits attribute and puts every part between the underscores in a list item.
ListSearcher searches the list using RegEx for 5 digits and returns 5_digit_number_index.
ListExploder explodes list.
Tester filters out the first two elements (index 0 and 1) and all the elements that share the same index or higher as the 5_digit_number_index.
Aggregator (grouped by ID) aggregates all list features together and creates a new list (Generate List: z_list).
Finally the ListConcatenator creates the output string of all string elements between the first two elements and the 5 digit number.
That do the work for me….thank you….but the listconcatenator is not necessary because to concatenate the attributes inside the aggregator also do the work







")
