Hi there,
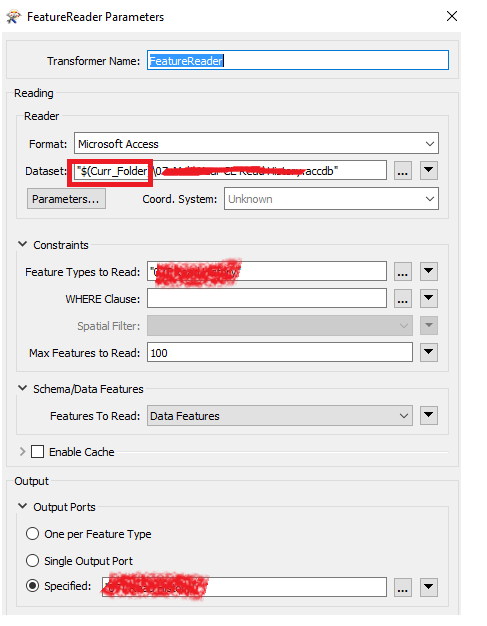
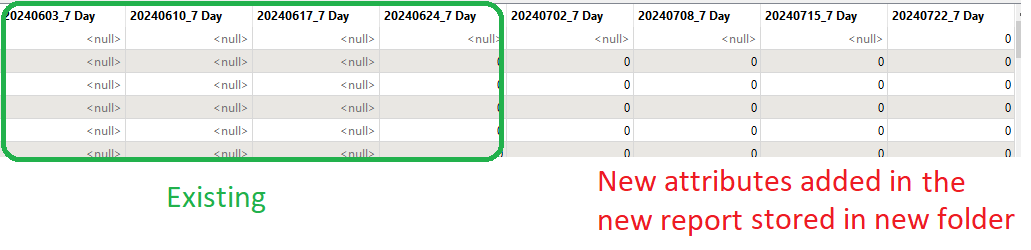
Can you please help me with this? Every time when a new report came in, I’d have to manually open the “FreatureReader” dialogbox and hit “Ok” (to close) so that the new attributes that are added in new report at the new folder location are emerged. Otherwise, it would just read previous attributes from the new report (in below case, up to the end of June, not the July columns).
I’m just trying read an MS Access file that is stored dynamically in different folder each month.