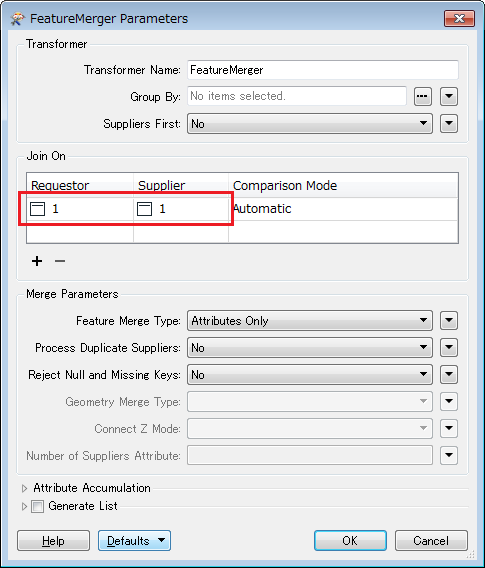
I have done a feature merge on two streetname lists. As output I now have two lists which contain streetnames that are missing/wrong in either list.
So I would like to continue by doing a fuzzy comparison and return to ListA the most probable candidate from ListB for each attribute.
It is likely there are just typos, and I will then find them. Where the probability is very low the streetname is most likely missing completely or superfluous in either list which is also useful information.
Thanks for any ideas how to proceed...