I have a large, relatively complex workspace that performs a few tasks - loads data, validates bearings, distances, areas, creates subsets of the data and then creates a number of reports, PDF, HTML and XML)
The PostGIS database is located externally on a separate hosted server.
On my laptop the workspace takes less than 2 minutes to complete. My laptop is a pretty stock standard HP, Windows 64 Bit with 8GB RAM.
I have published to FME Server Cloud and had a starter configuration established with 2 virtual cores and 4GB RAM. This configuration caused the server to melt down and the jobs just kept failing with no specific errors. I upgraded to the standard configuration with 2 virtual cores and 8GB RAM. The workspace failed after about 30 minutes and what appeared to be multiple cycles of attempting to run but still no errors in the log.
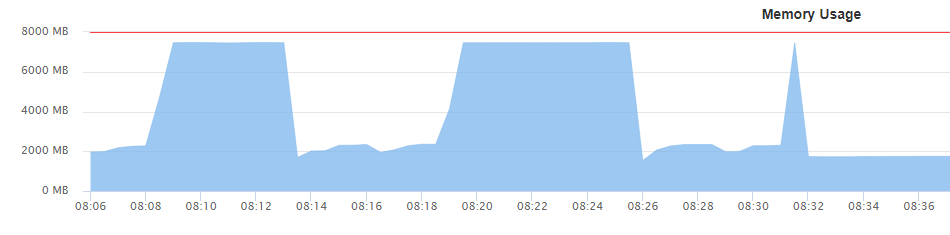
Below is the memory monitoring. The job was started at 8:06, memory peaked a couple of times and then finally failed at 8:36
What I am seeking is some advice / answers in three areas.
1. How do I determine what is the best configuration for FME Server Cloud?
2. What is best practice when it comes to creating a workspace regarding numbers of transformers, location of data etc.
3. What are the recommendations to improve performance for FME Server Cloud?
Update 26/08/19:
I did get the workspace to work when the resources where bumped up to Professional - 4 cores 16 GB, but it is still taking twice as long as the desktop version.

Update 27/08/19:
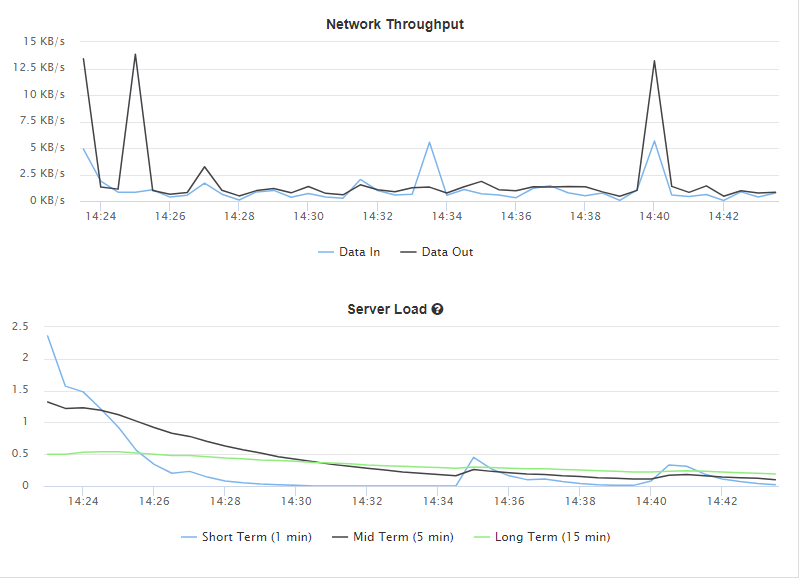
Data moved to FME Cloud PostGIS database and instance set to Professional. Speed has improved to around 30 seconds to run the validation. Network throughout spikes when creating reports but server load has reduced considerably. Job run at 14:40