Hi,
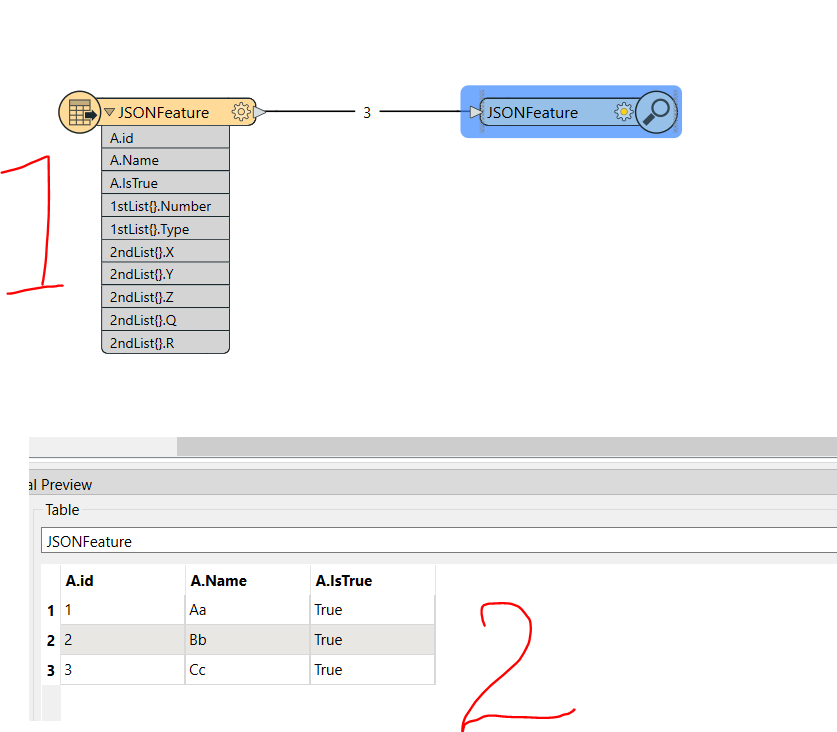
I have a JSON that I want to "flatten”, Currently, it has this structure.
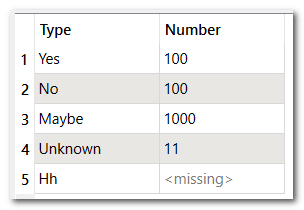
{"A":{"id":"1","Name":"Aa","IsTrue":"True"},"1stList":[{"Type":"Yes","Number":"100"},{"Type":"No","Number":"100"},{"Type":"Maybe","Number":"1000"},{"Type":"Unknown","Number":"11"},{"Type":"Hh"}],"2ndList":[{"X":"10","Y":"100","Z":"Abc","Q":"Def"}]}
{"A":{"id":"2","Name":"Bb","IsTrue":"True"},"2ndList":[{"X":"10","Y":"11","R":"100000","Z":"Efg","Q":"Klmo"}]}
{"A":{"id":"3","Name":"Cc","IsTrue":"True"},"2ndList":[{"X":"10","Y":"12","Z":"Lmno","Q":"Stuv"}]}Just reading it with the following parameter settings doesn't work:
Flatten Nested JSON Values into Attributes: YES
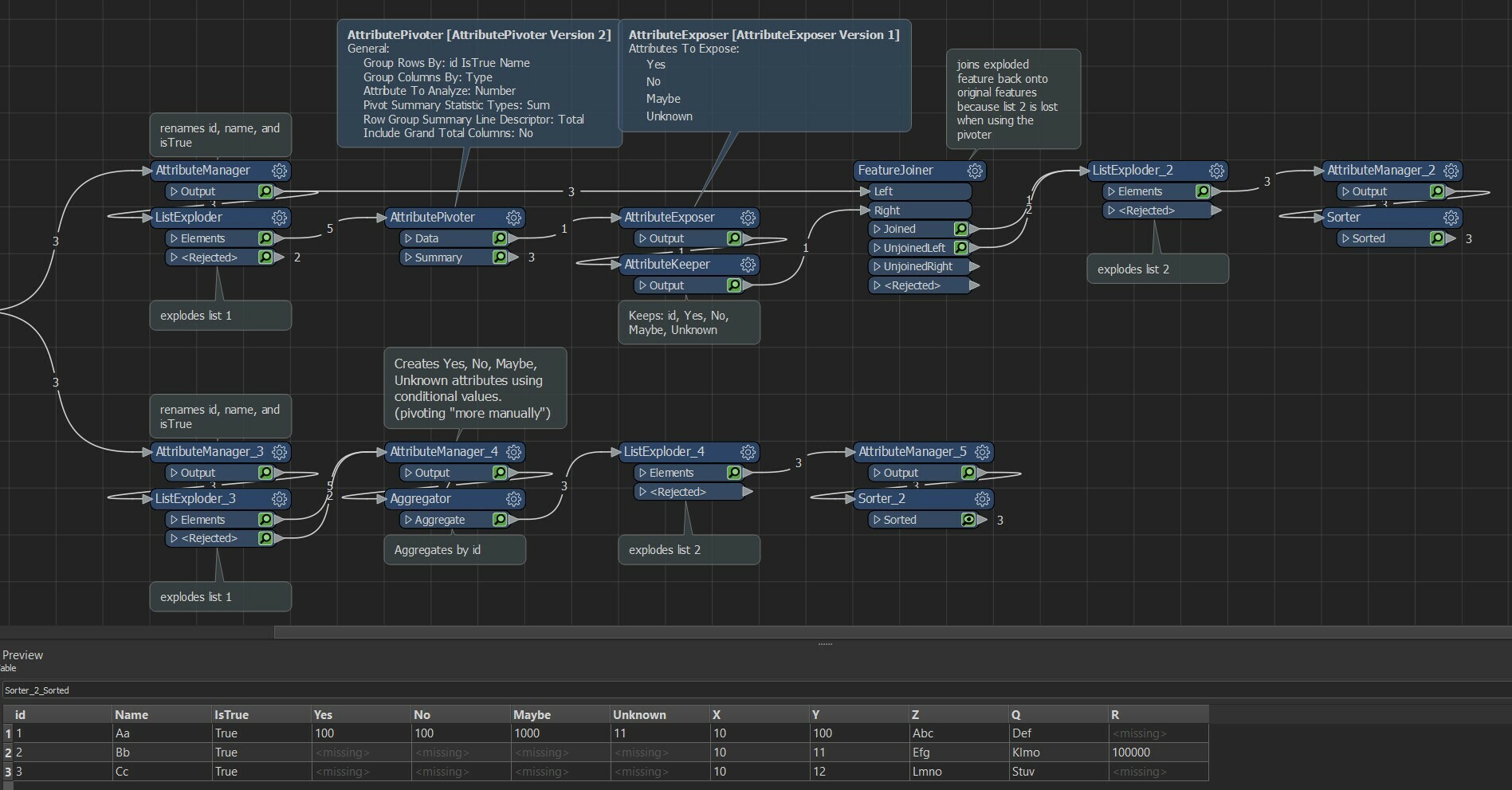
I've tried with 2 listexploders after reading, but that also doesn't give the correct result.
I just want the endresult to be a flat table. How can I best achieve this in FME?