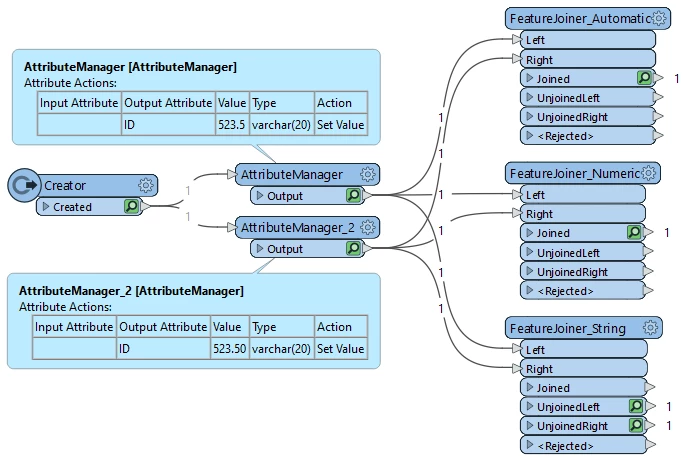
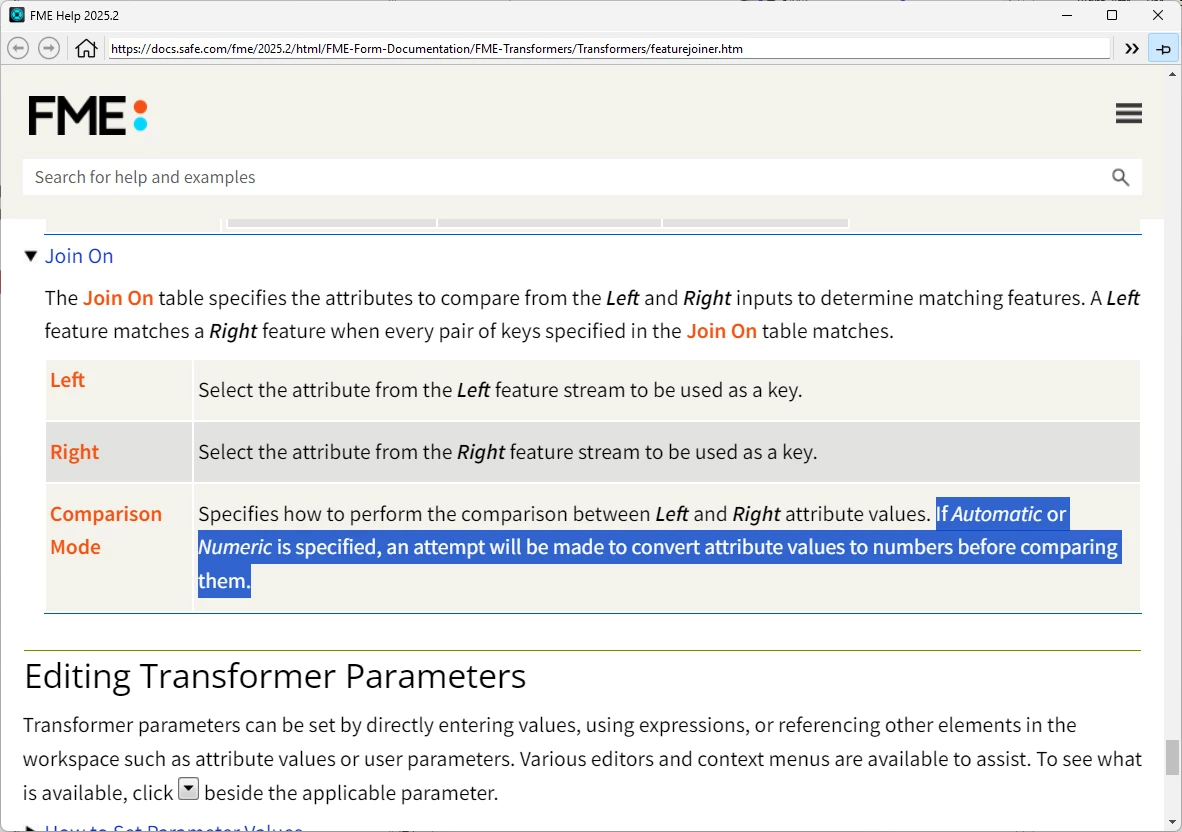
Using various recent versions of FME Form, I’ve discovered that a common key field that we use to join datasets on has a sloppy join when the FeatureJoiner Comparison Mode is set to Automatic.
Since Automatic is the default comparison mode and the results are not at all what I would expect, I find this somewhat concerning. One needs to get into the data a bit to realize that the join is happening in a sort of loose/”like” fashion instead of a clean match.
The key values are alphanumeric plus other characters such as a period or hyphen.
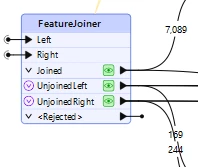
As an example, on a subset of data, these are the record counts with the default Automatic comparison mode:
And these are the record counts with the String comparison mode:
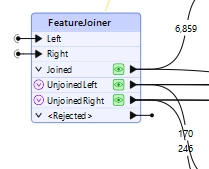
The Automatic comparison mode is joining ID values that are close, but not the same, at least in some cases by dropping a trailing “0” (or more than one trailing “0”) and making bad 1:M matches instead of the expected 1:1 matches. For examples:
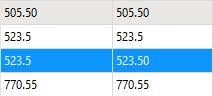
and
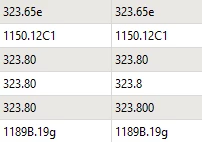
The above is in FME Form FME(R) 2025.1.2.0 (20250829 - Build 25630 - WIN64), but was observed at v2024.x as well, likely also in earlier versions.
While I understand that the Automatic comparison mode is doing the best that it can, and the issue can be resolved by switching the comparison mode to String in this case, I do wonder if this is of concern or interest to anyone else, and also if it could be handled better in the application. Perhaps the Automatic mode could be more accurate in its evaluation of the join field values, or else there could be a sort of warning or diagnostic to notify the workbench author that they may be getting significantly different results than one would expect.
I didn’t see anything about this in the documentation or the community, so wanted to see if others had any similar experience or input on how this could be better - assuming that I’m not misinterpreting something basic here.