Hi all,
So I have successfully read in a shapefile to FME and written it to our ArcGIS Enterprise Portal. What I next want to do is send an updated version of the shapefile into Portal, overwriting the existing version (as this feature will be added into maps and dashboards etc.). However I have tried to do this in several ways and it isn't working.
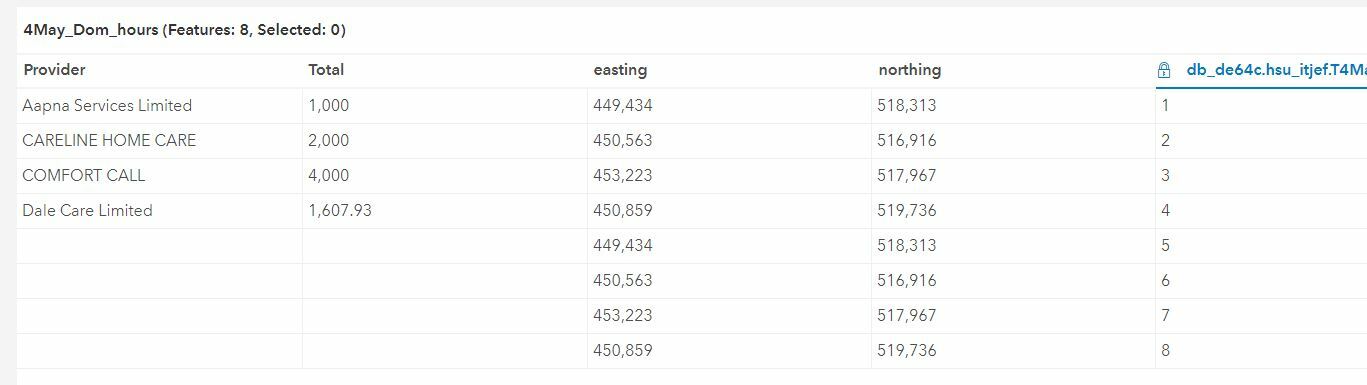
The shapefile is very simple, a 'provider field' a 'total field' and an 'easting' and 'northing' field. The provder field is likely the only attributes which will change, with the values changing regularly.
What I tried first was in the writer set the Portal layer to INSERT and Truncate the layer, but this resulted in the layer deleting all attribute values out of 2 of the 4 fields (provider and total)?!
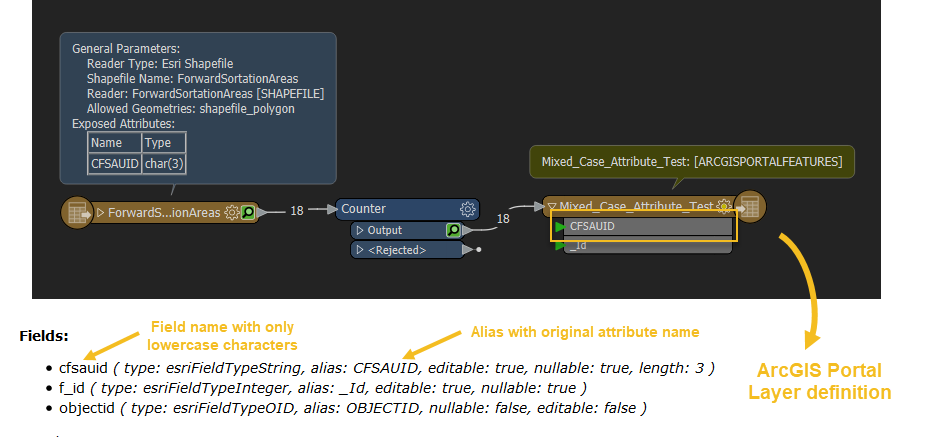
So I then tried setting the writer to UPDATE, this this failed as the shapefile doesn't contain a 'objectid' field. Although when I view the shapefile in ArcGIS, it does have an ID field, but if I view it in FME, it doesn't show. I tried to use the attribute manager transformer to add in a manual objectid field but it still failed. I also tried manually adding in objectid field in ArcGIS, but it wouldn't let me as it already existed.
I feel like this should quite a trivial thing to do, to basically overwrite an existing ArcGIS Portal feature, but I am having no luck!
Any help is appreciated :)
Thanks
Dan