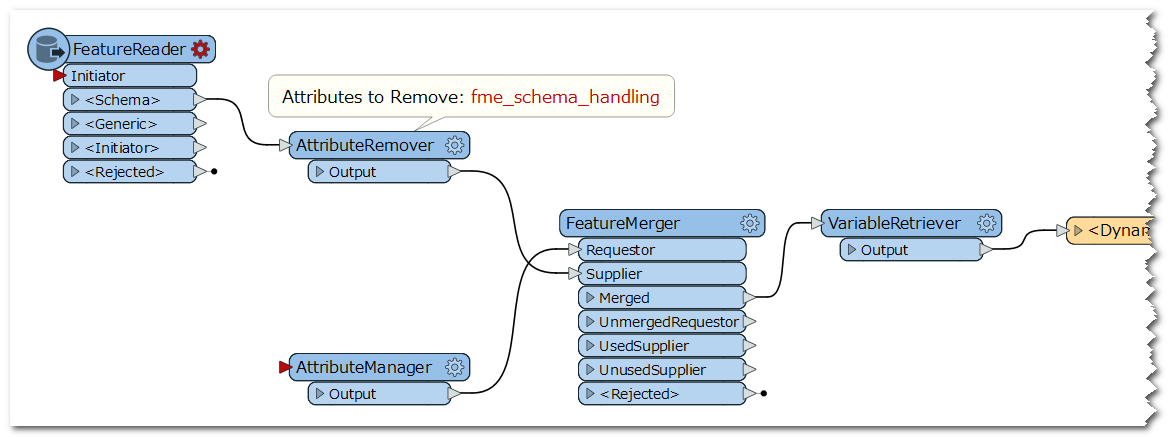
I have a workspace which reads rows from an excel file and writes the same rows to an other excel file using dynamic schema definition. Gets the schema from the excel file which is read. My problem is that the first row that is read is skipped in the writer. In the attached example the output will only contain the second row of TestExcelWriter.xlsx
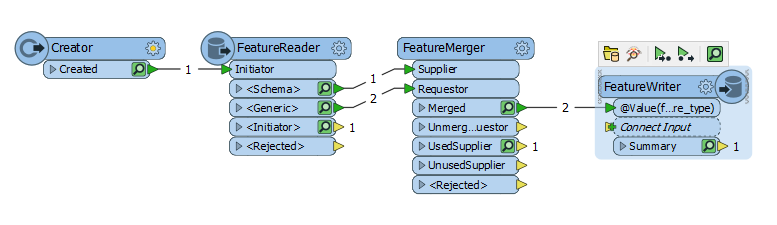
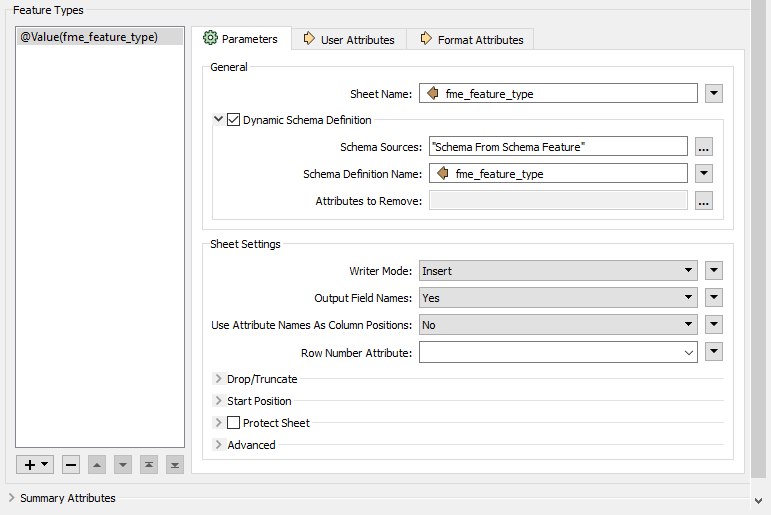


 On the left upper part is the dynamic reader, on left down part is the data I want to write.
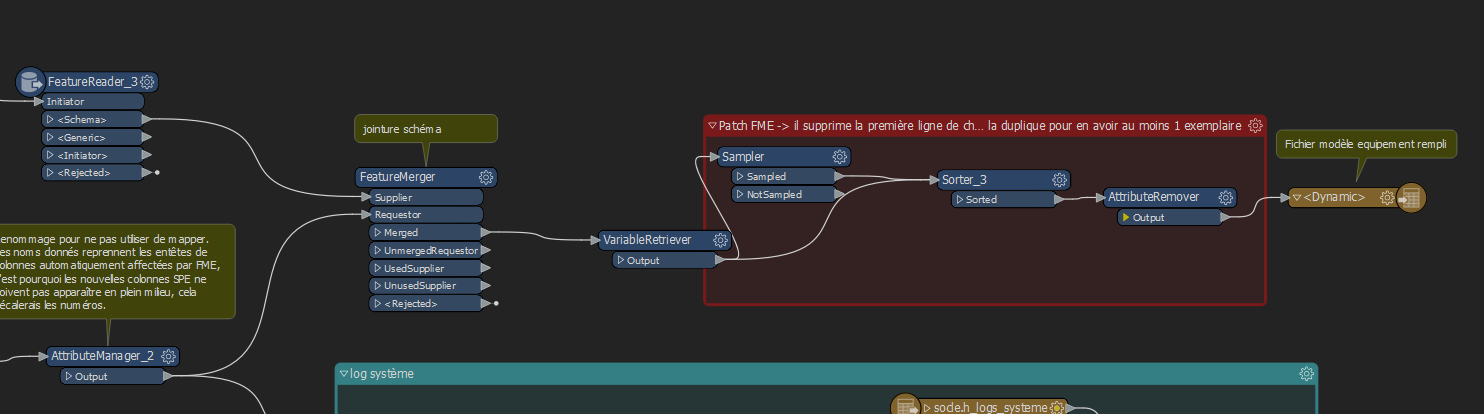
On the left upper part is the dynamic reader, on left down part is the data I want to write.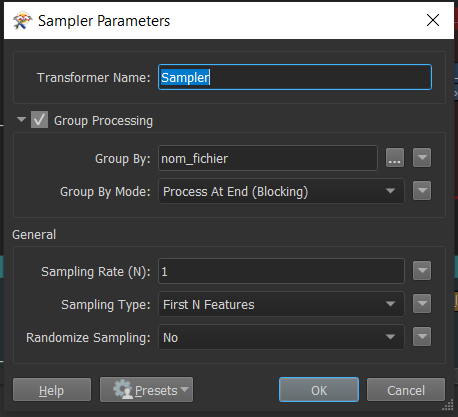 Then I sort them again (because I don't know if all the duplicates are written at the end or "at the right place I want them to be")
Then I sort them again (because I don't know if all the duplicates are written at the end or "at the right place I want them to be")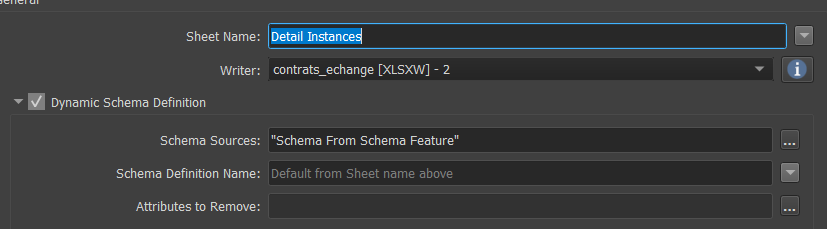 I just start writing at the 10th line in the excel, the rest is not changed.
I just start writing at the 10th line in the excel, the rest is not changed.