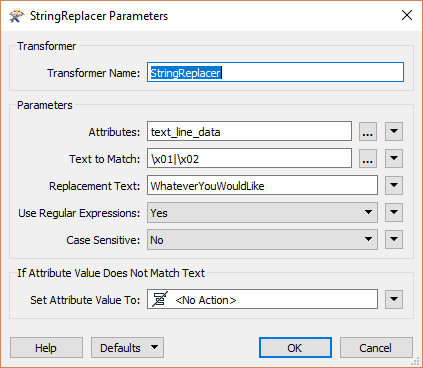
I have several CSV files exported from Hadoop so the separator is the SOH control character. What do I type as the separator for the CSV reader? I've tried the hex code (\\x01) and copying/pasting the SOH character from Notepad++ but neither work.
Thanks,
Aaron