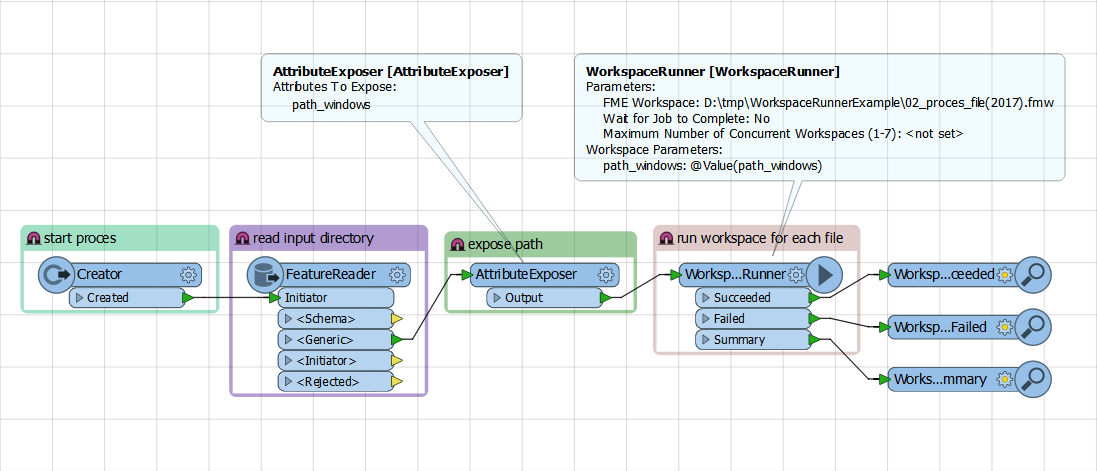
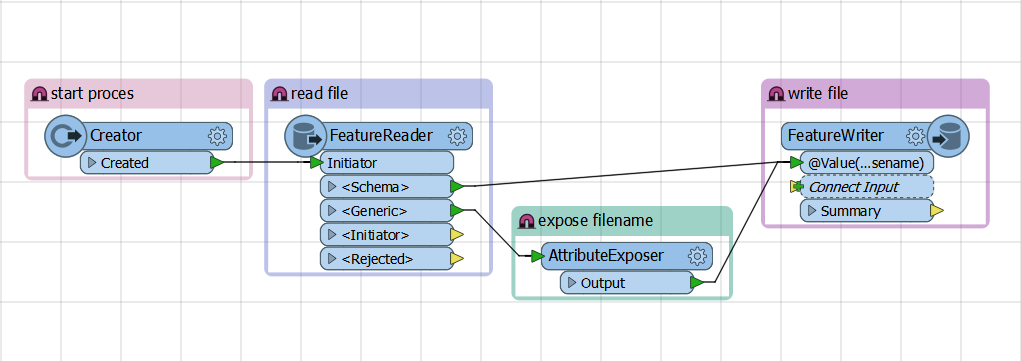
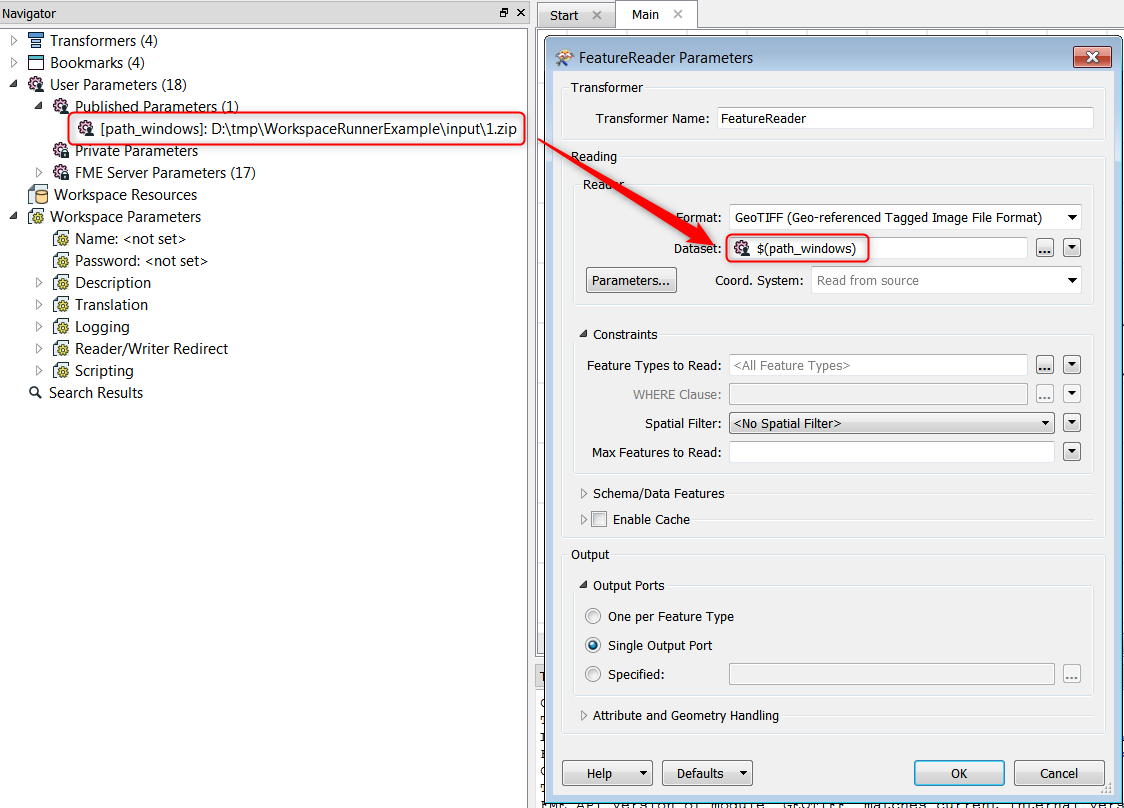
I have 1.6TB of .tif files.
Each file (11,500 of them) are named numerically and stored in individual .zip files.
I need to convert all of the .tif files to JPEG2000.
So far I ran the tif to Jpeg2000 reader/writer through the batch Deploy on small test runs of 10 files and it worked just fine. But when I run the full meal deal FME freezes.
Please Advise