

Hi all,
I would like to know how I can simplify some work that I do now in Excel with a very complex formula.

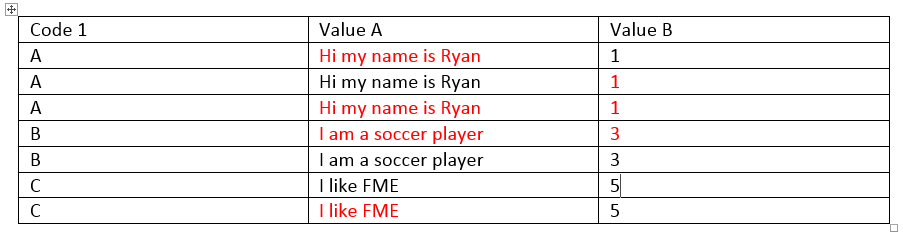
What I want to do, is to "compress" a table. I made an example above (not the kind of data, but the idea is simple). Code 1 is leading, and is a code for a certain spell. Value A and Value B are pieces of information that belong to Code 1, but some information is fragmented and/or absent in some rules.
What I want, is that I will get one table like this one:
In this way, I can just use the DuplicateFilter to extract just one random Code1 feature to get the compressed data set I want, including all information.
Does anyone have a suggestion? In Excel, I just took the longest answer for every cell and per Code 1, but I would like to do this process in FME since it will be way faster for larger datasets I assume. Besides that, my Excel formula had to be six sentences long in order to cover the right range for Code 1, consuming a lot of computation time.
Regards,
Martin






