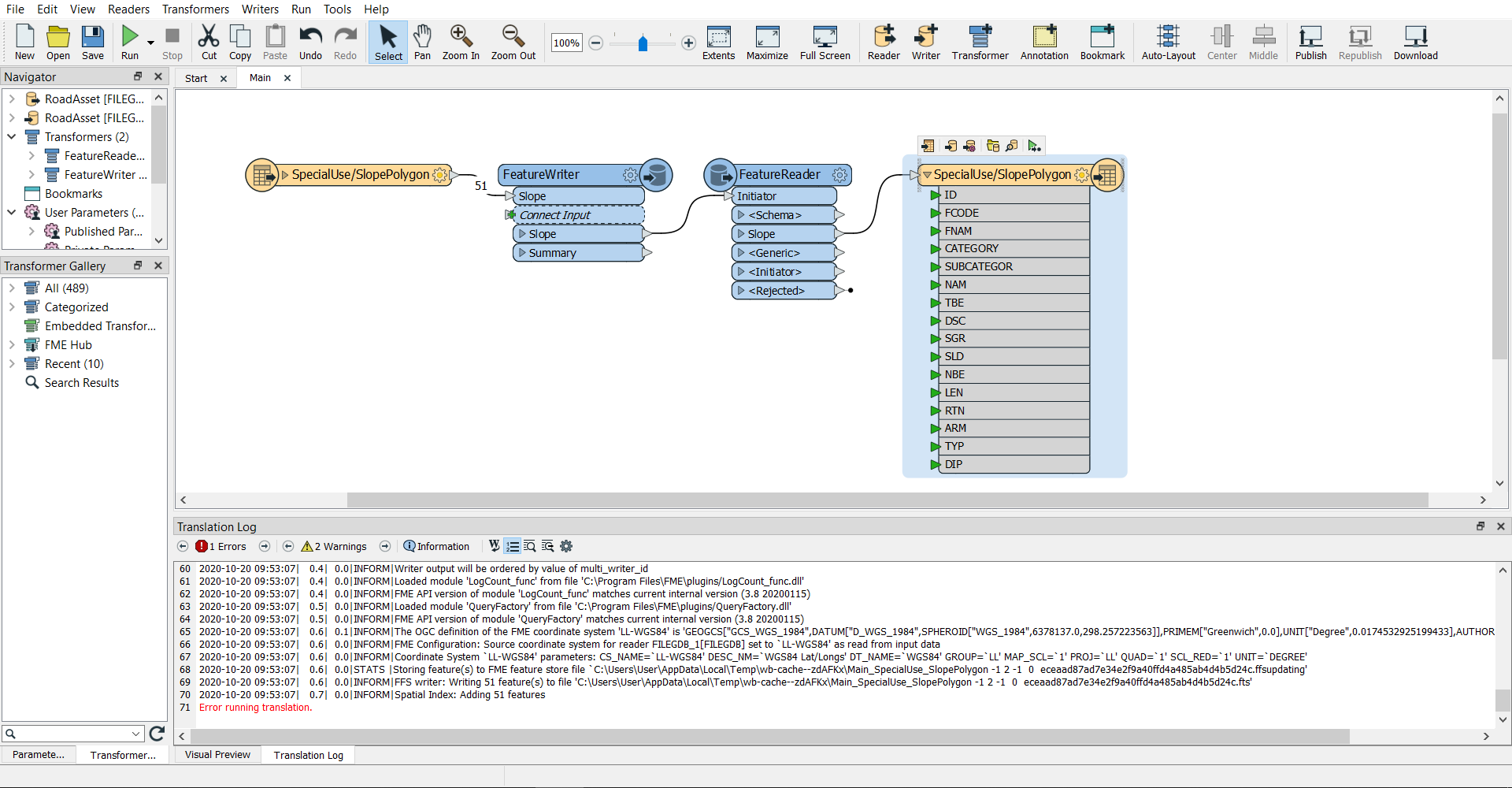
The likely reason is because there is a Schema Lock on the FGDB. Until any Read processes have finished reading from the FGDB and released their Schema Locks, then data can't be written to the same FGDB Schema objects.
In your workflow, you have "Slope" as the Initiator that is initiating a downstream FeatureReader 51 times and then trying to write to the same FGDB 51 times with what appears to be the same data, so it is likely the first FeatureWriter hasn't released its Schema lock before the workflow attempts to commence the Final Writer on the same FGDB Feature Class.
To step back somewhat and look at the overall Workflow design, on first impressions this seems a very convoluted way of performing Updates/Inserts and not the way most workflows would do this.
Most workflows would Read the data in with a single Reader (or single FeatureReader), transform the data inside the Workflow, and then write any Inserts/Updates with a single Writer (or single FeatureWriter). So I can't see why there is a need for any intermediate FeatureReaders or FeatureWriters here.
For FGDBs in particular using this conventional method makes the Workflow:
1st: Read all the required data into FME Memory/File Cache, and then close the FGDB connection and Remove Schema Locks
2nd: Open an new FGDB connection and write the data
Which generally avoids and Schema lock issues on FGDBs