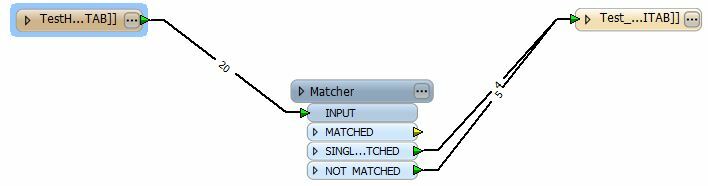
I am going to be upgrading to FME 2013 today, and after doing so, I was wondering if anyone could lend a hand in telling me if FME can provide what I'm looking to do.
1. We stored all data in a MapInfo .TAB file (flat files) for each customer
2. Customers will give us new data on a weekly basis; however, the data being given includes everything from the first submission, and then perhaps some additions that are legitmate. In doing step 2, the customer is actually creating duplicate objects stacked on top of the first upload.
My question is can FME run a process to find and eliminate all those duplicate objects so that only one remains (since the others are useless).
Thanks for any insight in advance.
Nick