



I noticed some strange behaviour while exporting some simple data to shapefile: when using the "tech preview" (writer of featurewriter) my attribute name and values are trimmed to one character...
I've read this format is still under active development, but as i couldn't find it as a known issue: is this a bug or am i doing something wrong?
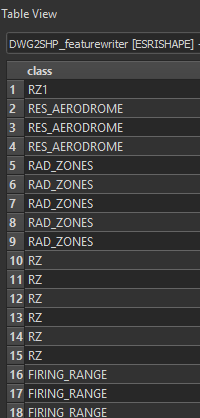
expected output (using the 'classic' shapefilewriters):
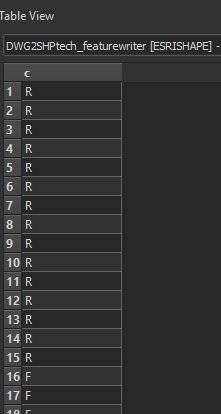
tech preview output:
using FME(R) 2019.1.3.0 (20191007 - Build 19642 - WIN64)
example workbench:

