I did a full run directly, without FeatureCaching. I'm not reading the wrote files during the process. Basically, the script creates 3 different feature types for every file, and merges them together:
It first writes the terrain in a glTF file, then the buildings and then the trees, in the same file again. The weird thing is, it works on small datasets (16km^2) but not on larger ones. That's why I wanted to know if there was a known issue with FME that resctricts some things based on memory usage, or maybe a UNIX problem that prevents writing too many files in the same folder. The latter shouldn't be the problem as the same script works for file based datasets (IFC and OBJ), where I output more than 20'000 files in the same folder.
No experience with these formats, but if I read:
It first writes the terrain in a glTF file, then the buildings and then the trees, in the same file again.
I wonder, can it be that multiple writers are writing to the same file, at the same time? Because if that is the case, this is probably causing the access denied error.
This can work in a small set where due to accidental timing it works fine, but with a production run, with a lot of data and different timing, this can fail.
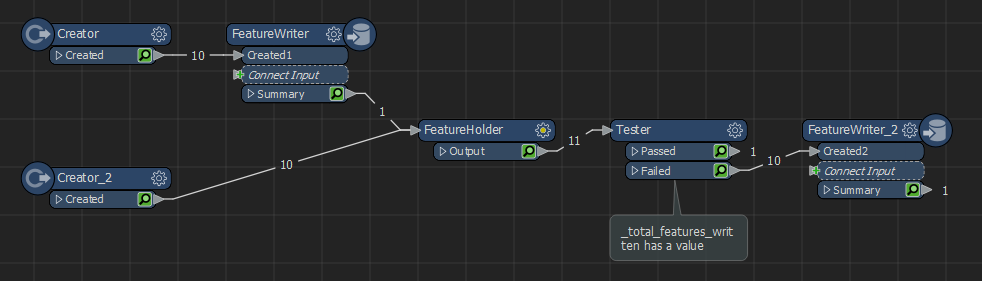
It is possible to force one FeatureWriter to wait for the previous one to finish. Connect the second FeatureWriter input and the first FeatureWriter summary outputport to a Holder, then a Tester to remove the summary feature from the data, send the rest to the inputport of the second FeatureWriter. Downside is this might take a lot of memory, due to all features waiting before they can move on.