Hi everyone,
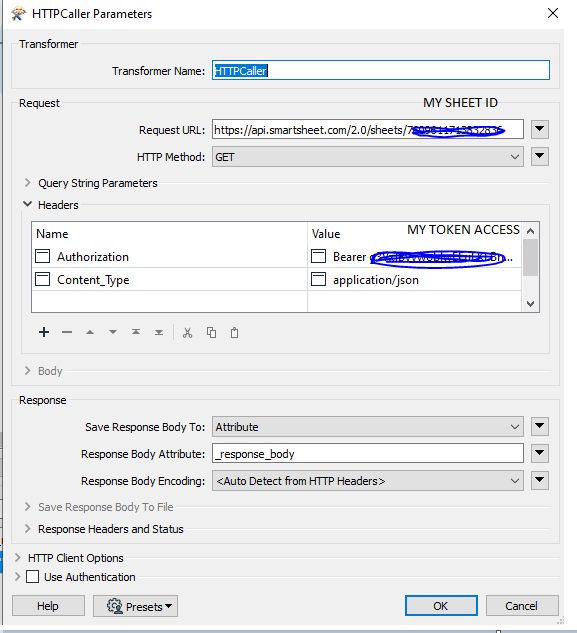
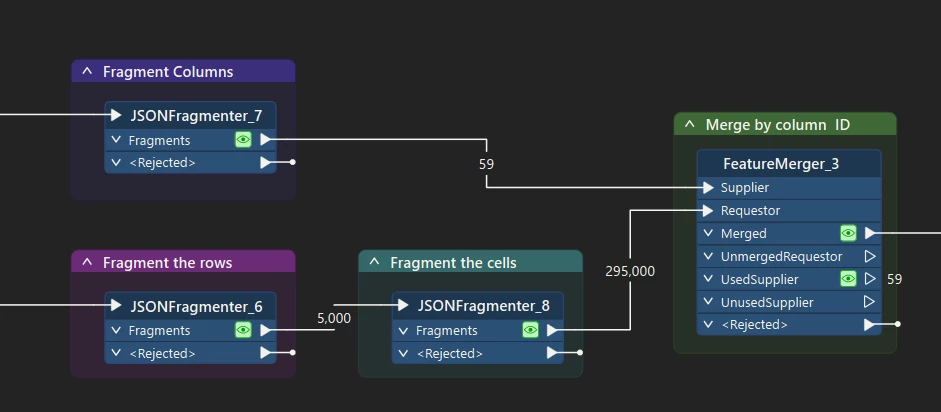
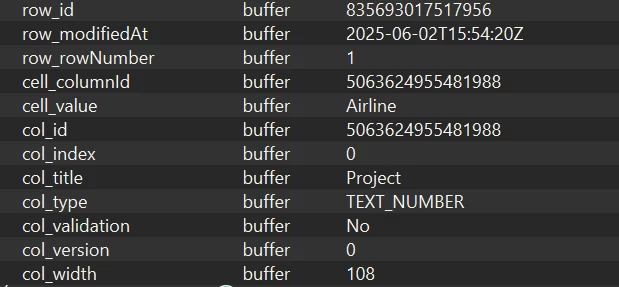
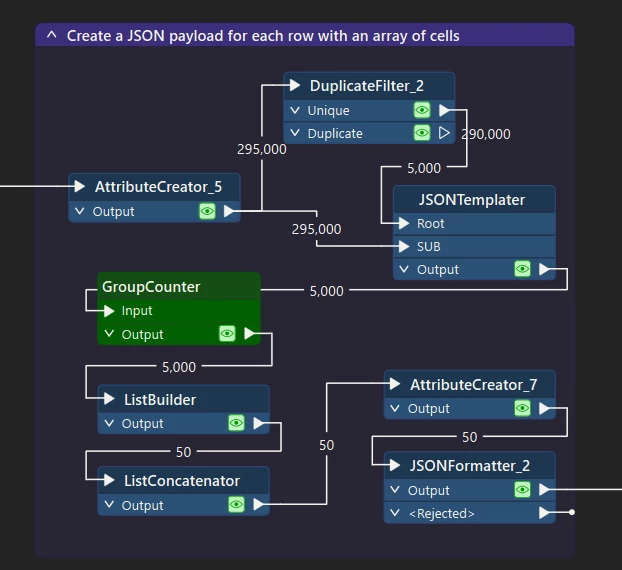
I have a task to automate a process which starts with a Smartsheet. I’m somehow new to FME. Does anyone know how can I add the Smartsheet to my workbench as a reader.


 +5
+5Hi everyone,
I have a task to automate a process which starts with a Smartsheet. I’m somehow new to FME. Does anyone know how can I add the Smartsheet to my workbench as a reader.
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.