




I wanted to share a project I’ve been working on : a way to "watch" a PostgreSQL table using FME Flow Automation.
Since I began working with FME Server/Flow, Automation has always stood out as one of its most powerful and easy-to-demonstrate features.
The ability to trigger workspaces based on incoming emails or new files and automatically send notifications, consistently makes an impact during demos.
But one question kept coming back:
“Can I detect changes in a database table and trigger workspaces from that?”
For a long time, my answer was: “Not really”, or at least, not in a clean or recommended way. I used to think the best option was for the database to notify FME Flow, not the other way around. For instance, in PostgreSQL, you could use a trigger on insert/update/delete and call an FME Flow webhook using something like the PL/Python or pgsql-http.
That method is covered here:
- 🔗 4 methods for tracking data changes in FME (blog post)
- ▶️ Triggering FME with your Database (YouTube video)
So why not let FME Flow handle the detection itself? Mainly because that typically involves maintaining a duplicate of the table somewhere that FME Flow can compare against. That means double the storage, plus a possible security issue. Your duplicated table may not have the same access controls as your production one, and sensitive data could leak.
But then I had an idea:
What if the “duplicate” table didn’t store the actual data, just a CRC hash representing each row’s content?
A CRC hash (Cyclic Redundancy Check) is a lightweight checksum used to detect changes or errors in data.`
It’s not cryptographically secure (like SHA-256), but it’s fast and perfect for spotting changes.
Thankfully, FME makes this easy with the CRCCalculator transformer.
This way, storage is minimal and no sensitive data gets duplicated.
I built an FME workspace that can monitor any PostgreSQL table and detect changes between two executions by storing the CRC hash on a local SQLite database.
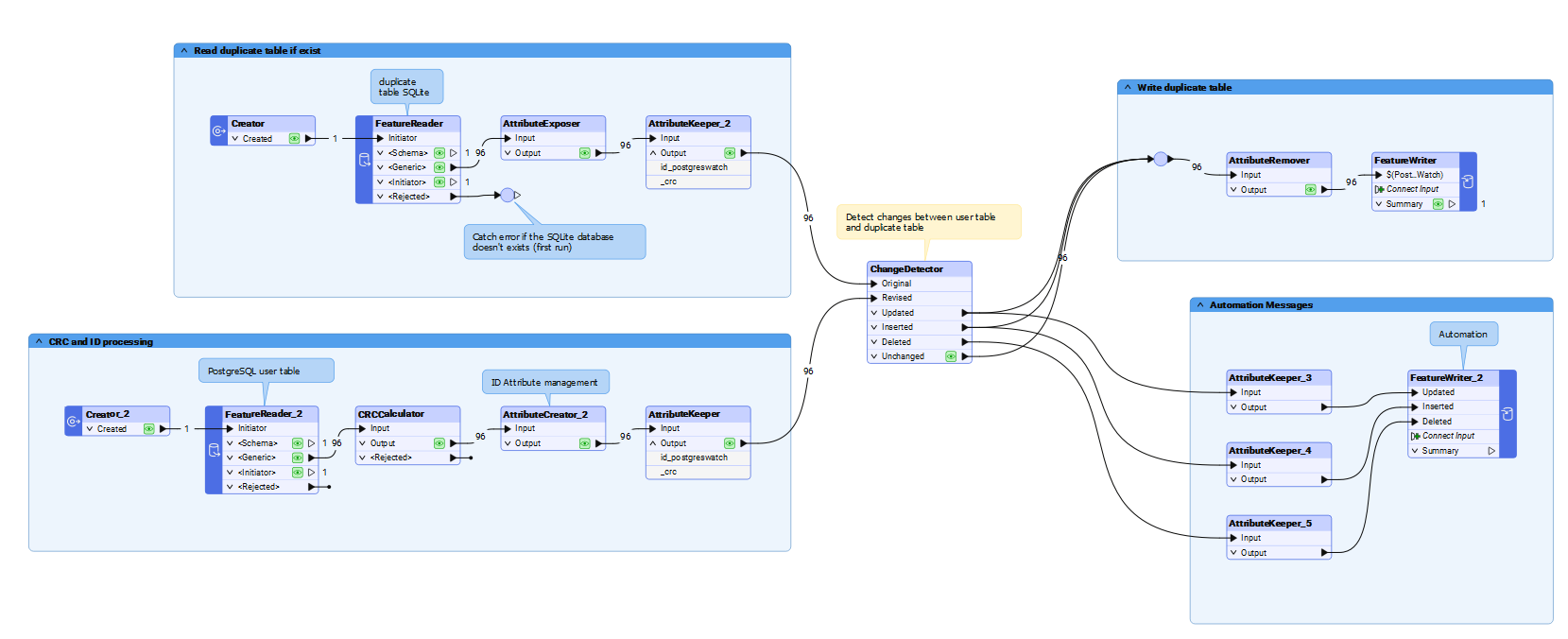
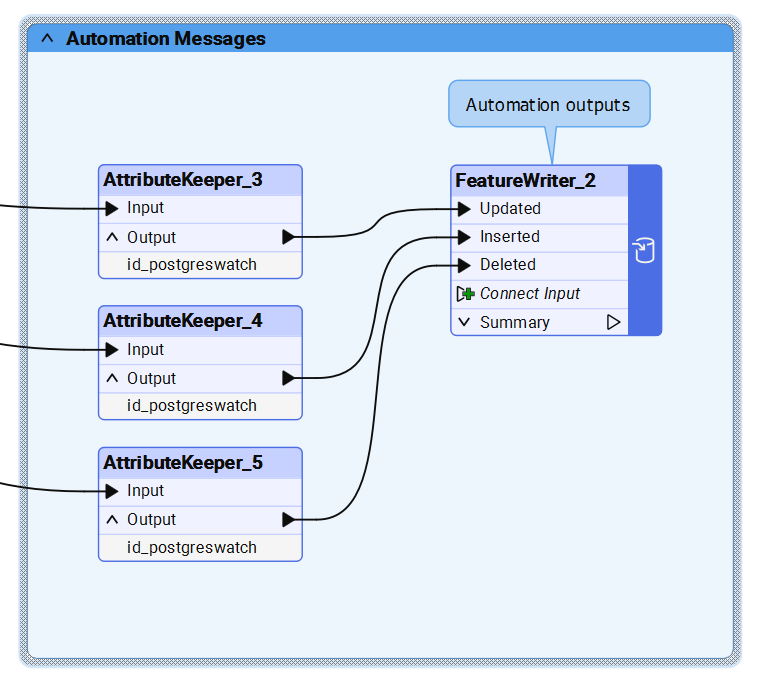
It outputs the detected changes using Automation Writers: one for inserts, one for updates, and one for deletions.
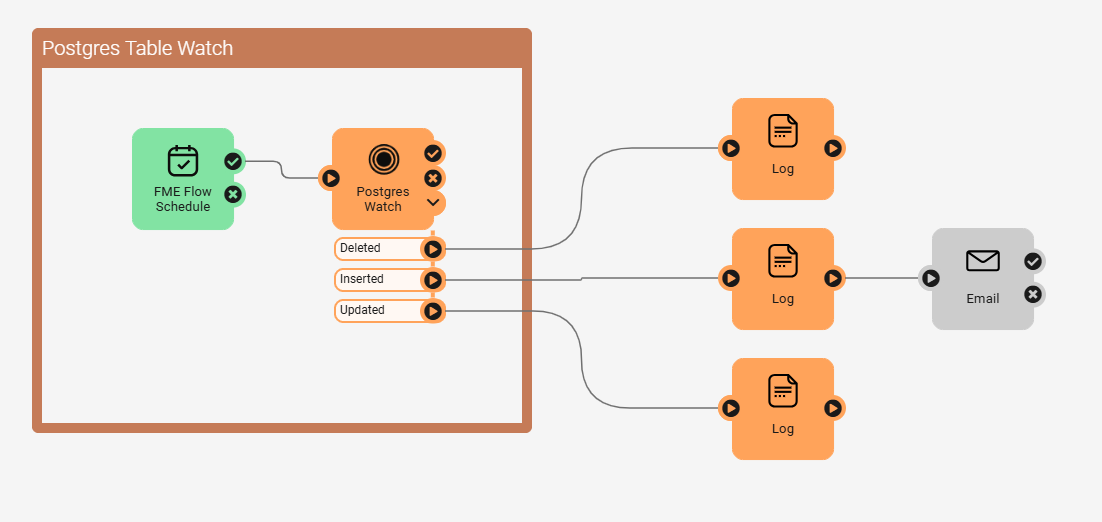
You can pair it with a Schedule Trigger in FME Flow to define how often it runs.
The challenging part? Making it generic enough so that users can plug in their own table without modifying the workspace.
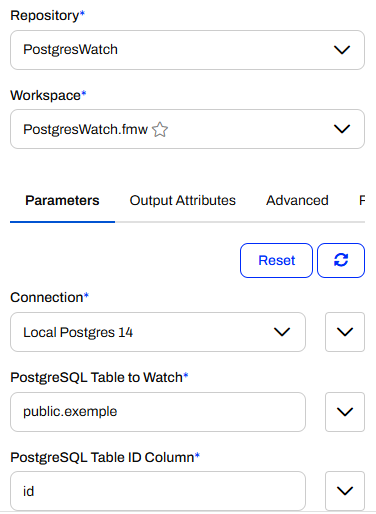
The workspace uses three user parameters:
Connection: A database connection parameter so you can pick from available PostgreSQL connections in FME Flow. That works well with the new connection storage based on FME Flow.
PostgreSQL Table to Watch: The fully qualified name of the table to monitor (e.g., public.my_table).
PostgreSQL Table ID Column: The primary key column used to identify each record.
Only the ID column is stored in plain text in the tracking table. It’s needed to detect updates and deletions. The Automation Writers output this ID so it can be used downstream
You can find the PostgresWatch FME Flow project on FME Hub here:
https://hub.safe.com/publishers/abizien/projects/postgreswatch
There aren’t many FME Flow projects on the Hub yet (only 8 at the time of writing, 6 of which are from Safe themselves), so I’m happy to contribute!
A limitation of this approach is that it requires an FME Flow engine to execute the workspace and perform the change detection.
Unlike most native Automation triggers, which can idle without consuming engine resources, this one actively runs at each interval.
While CRC collisions are extremely rare, they are theoretically possible.
So this is a trade-off between performance and absolute certainty.
I haven’t tested it yet on large datasets.
Depending on the size of your table and how often you run the detection, performance could become an issue. Especially if hashing and comparison involve thousands (or millions) of rows per run.
This project is still in early stages and hasn’t been tested exhaustively.
If you give it a try and run into any edge cases or have ideas for improvement, I’d love to hear about them!

