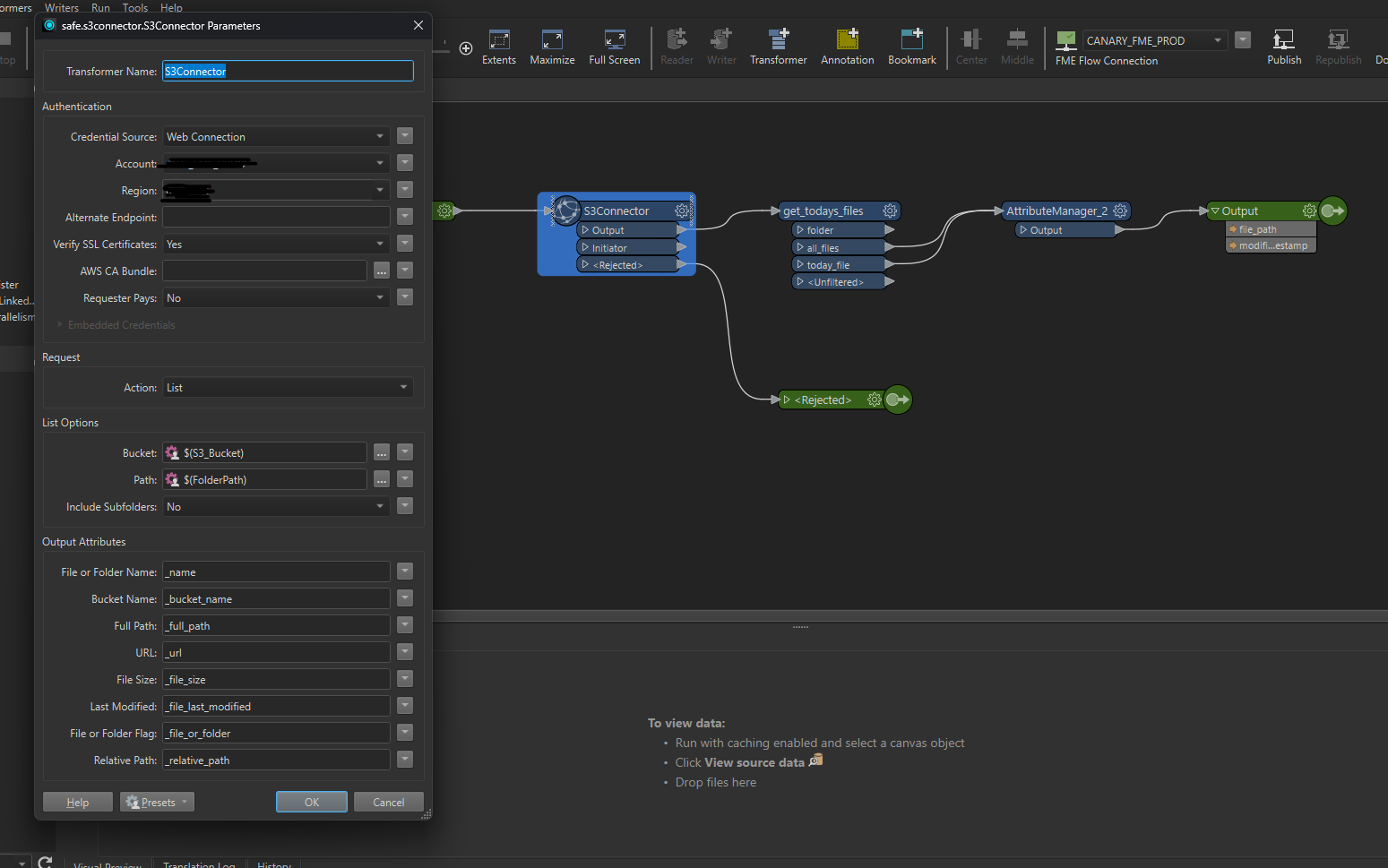
I have multiple files landing in a folder that is watch to trigger a wksp.
2 files go together but don't always have exactly the same name. (they will be similar.) There will also be multiple folders where these files can land and be processed. I need to know several things.
1 idea for parsing the file names of separate file types to get them matched into the same wksp. like maybe they land at the same time?
2 is it possible to use 1 automation to watch and file both file types and use them to kick off 1 wksp? image 1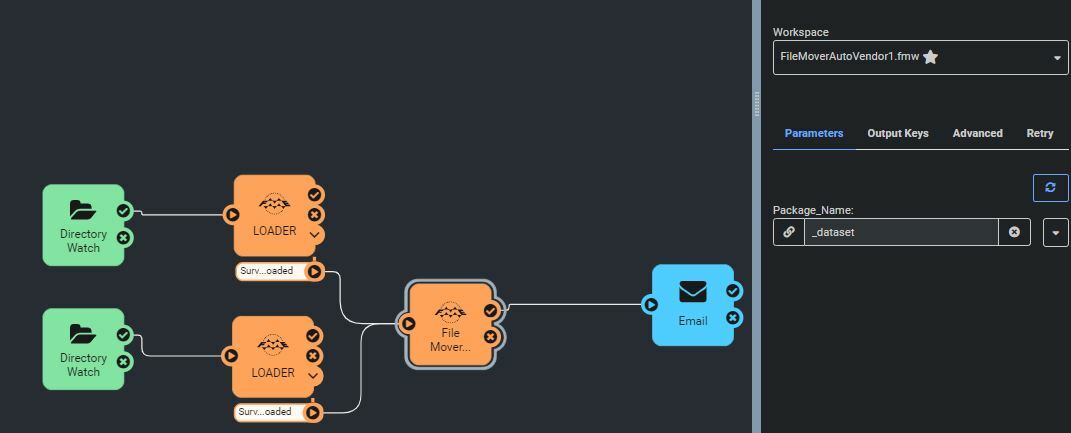 3 all the jobs coming in will be moved to 1 of 3 folders when process is complete using a file mover. Do i need three qutomations in my wlrkspace to tell the file mover where to move the package (both files) or can this be done with the dataset value (being parsed in the file mover wksp? see image 2
3 all the jobs coming in will be moved to 1 of 3 folders when process is complete using a file mover. Do i need three qutomations in my wlrkspace to tell the file mover where to move the package (both files) or can this be done with the dataset value (being parsed in the file mover wksp? see image 2  IT is also possible that files will land in both incoming locations at the same time. the file types would be the same but the file name would be different
IT is also possible that files will land in both incoming locations at the same time. the file types would be the same but the file name would be different
I found some information about the filecopy but really need help with the first part of this!
https://community.safe.com/s/question/0D54Q000080hHKOSA2/am-i-using-filecopy-correctly
- If you have multiple output folders you can set
- Destination File Copy Folder : NotUsed
- filecopy_source_dataset = server 1
- filecopy_dest_dataset = server2\\subfolder (where subfolder is different for each feature)