This was got to work in the end. Overall the run time reduced from 1'30 down to 2.5 seconds. Thanks to @edgarrunnman and @david_r for their suggestions. I'll answer my own question to close this off. The use case was implemented on MS SQL server but should apply to other RDBMS as well.
The steps are firstly to create a temp table via a SQLExecutor with the SQL Statement:
FME_SQL_DELIMITER ;
create table $(targetTempTable)
(variableName varchar(7));
In this case I have used a private parameter for a temp table name which in SQL server starts with #. This removes the need for the end user to have to worry about the name and ensures a temp table is created. Temporary tables are dropped when the session that creates the table has closed. (Details)
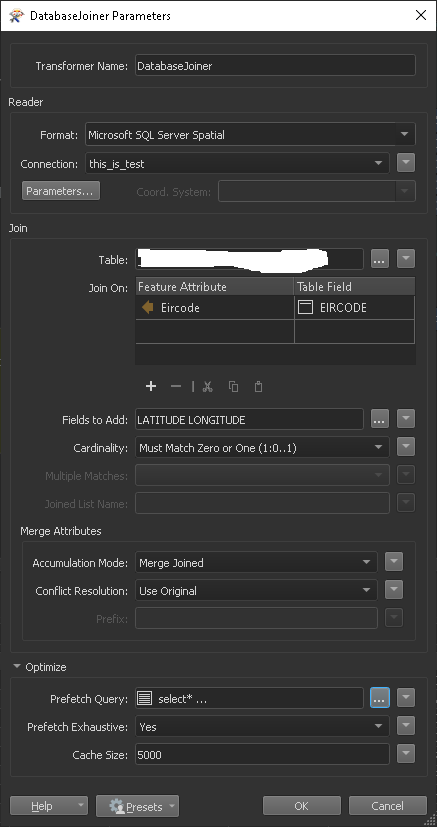
Once the table is created you use your input to populate your temp table with the values you want to use as a filter on the data base joiner with an exhaustive prefetch query:
select*
from SomeDataBaseTable
WHERE eircode IN
(SELECT eircode from $(targetTempTable))
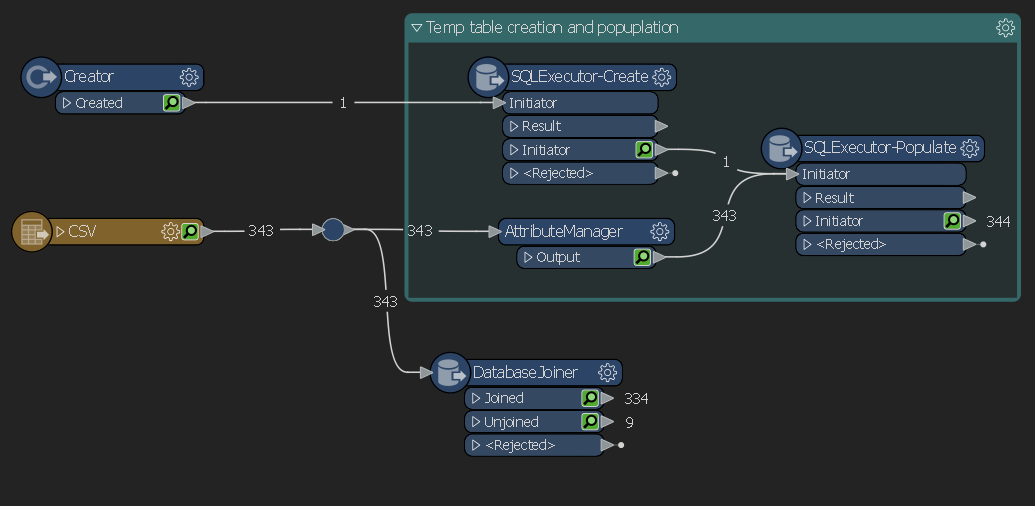
 The entire workflow is below
The entire workflow is below




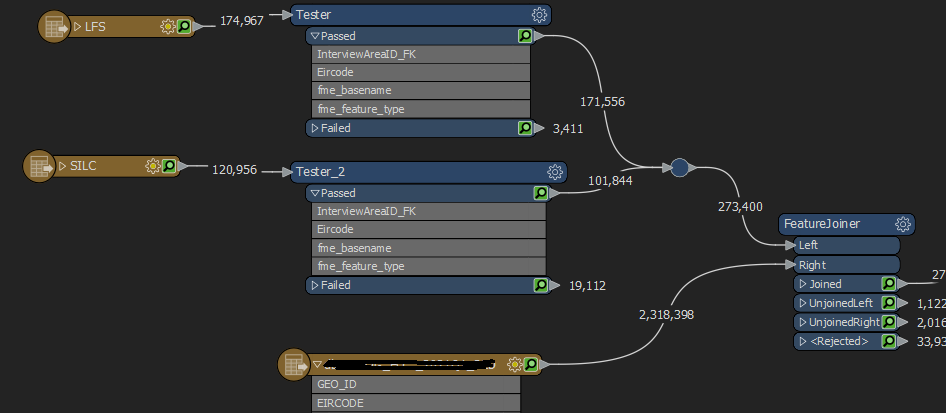 What I think should be possible but I'm not sure how to implement it is to create a temp table and use that as a subselect or joined table to get the data using a SQL query
What I think should be possible but I'm not sure how to implement it is to create a temp table and use that as a subselect or joined table to get the data using a SQL query 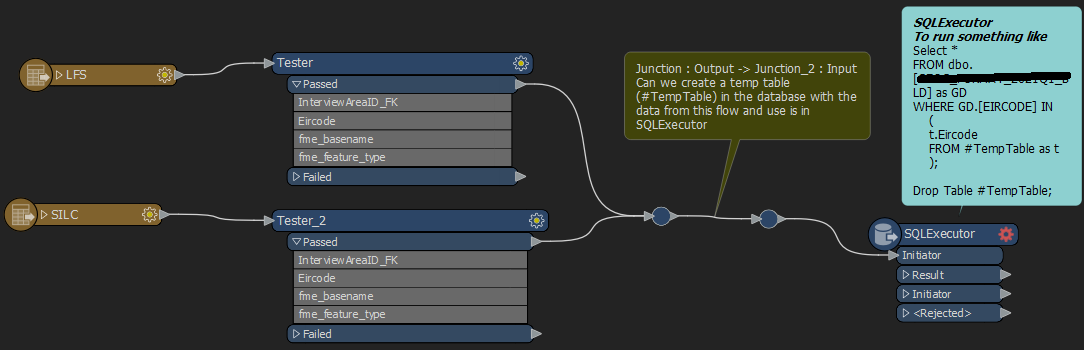






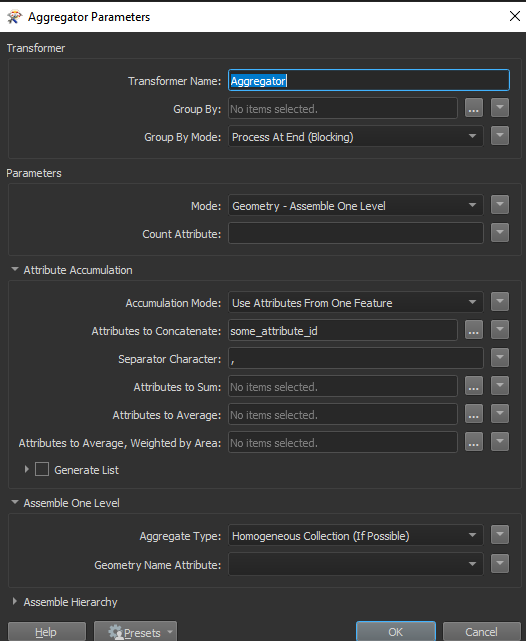
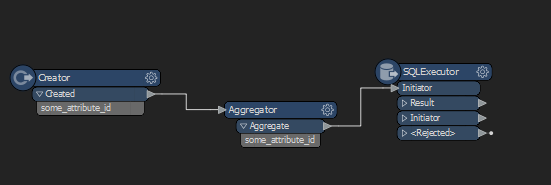
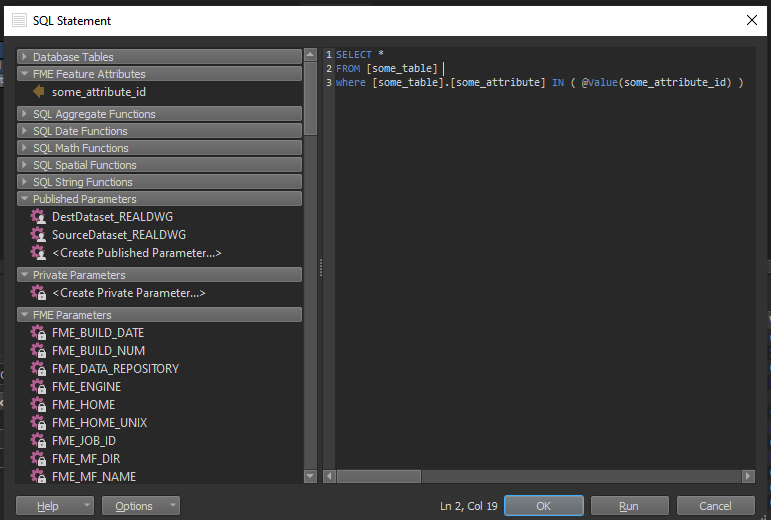 you might need some modification to aggregated attribute if it's of text type. (this should work for int)
you might need some modification to aggregated attribute if it's of text type. (this should work for int)
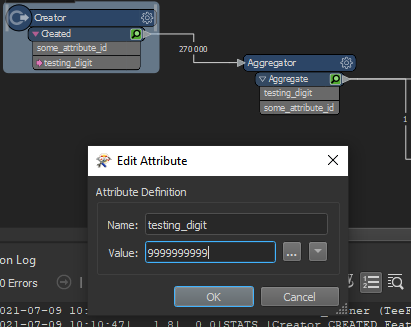 if SQL query is not buying it try group features and use
if SQL query is not buying it try group features and use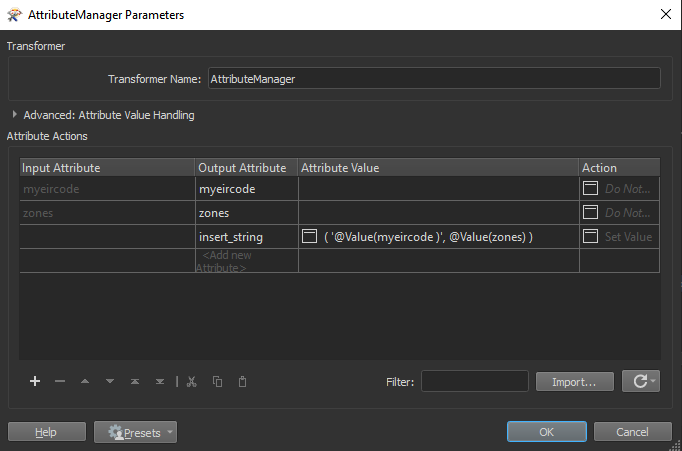 and then
and then