


Hi All, I have a strange one i think!
Its a simple workspace which takes a Spatial SQL table of property boundaries and reprojects it before writing to a mapinfo tab file. Running the workspace on workbench (same server) gives the correct results, running it on fme server produces a tab file which is from what i can see 99% correct, but muddled up in places.
- Confirmed Server workspace and Workbench are identical
- Deleted server workspace and published from workbench again - same results
- Server job log doesn't give any indications to any issues - features written are same
- Restarting server does nothing (Express installation)
- workbench & server are same version 2022
Heres the weird bit!, if i inspect the tab file after running the workspace on fme server it seems to have swapped the attributes of about 13 spatial features around and muddled them about. Screenshots might give a better idea.
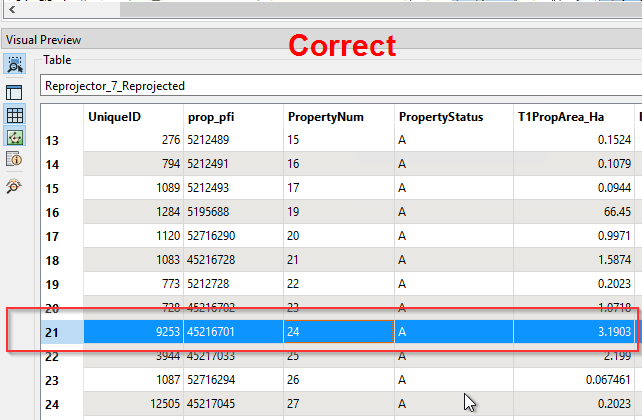
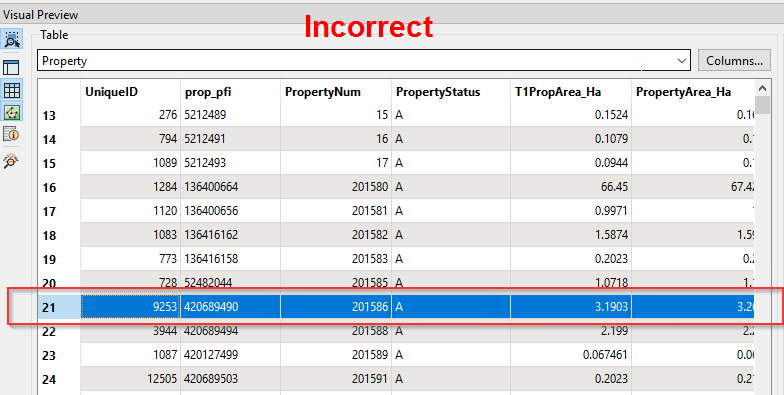
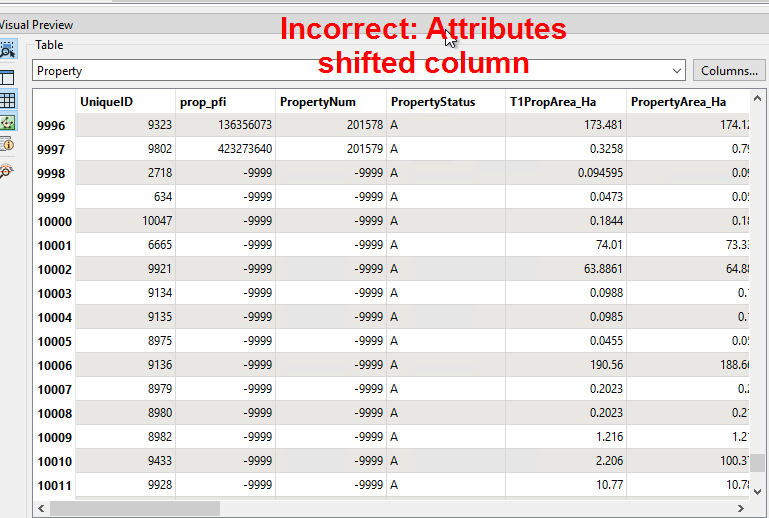 Any suggestions are appreciated!
Any suggestions are appreciated!


