This question is related to this earlier post on handling several CSV files output to the server shared data directory: https://knowledge.safe.com/questions/79707/fme-cloud-workflow-for-moving-media-zip-files-betw.html
@GerhardAtSafe has greatly helped me with several aspects and I'm continuing to research and learn what I can, but I'm having trouble figuring out the best way to handle multiple CSV files output to a single directory under the shared data directory on server. Not all the CSV files will be written on the scheduled jobs, and the number of separate CSVs that could be written is between 0-23 files. These are output from a series of jobs that run on a weekly schedule to update tables in a PostGIS database.
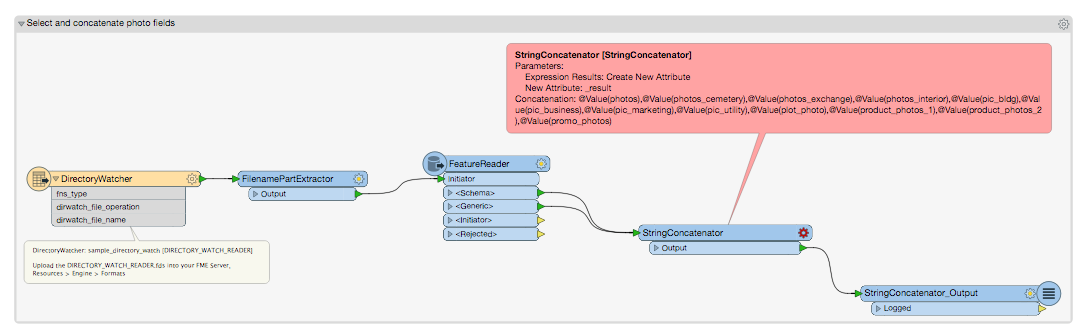
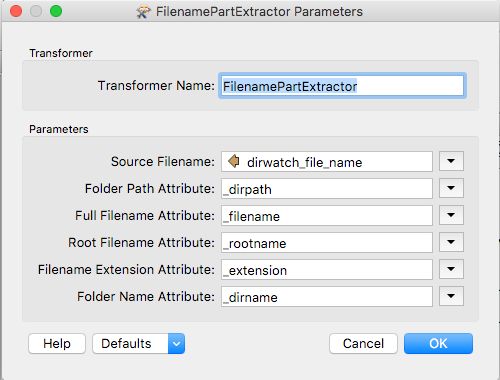
I want to use these CSV files to trigger a job which parses media pulls from an S3 bucket, zips that up and pushes to another S3 bucket or UNC path. The problem I'm struggling with is how to read each of these CSV files individually in order to select the correct columns for parsing the media ids. I'm not sure if reading these in dynamically with a CSV reader or a FeatureReader transformer is best possible solution. I've attached 2 screenshots below of the workspaces which perform perfectly on individual CSV files for parsing media ids and using that output in a FMEServerJobSubmitter on the next workspace which pulls that media from the S3 bucket and uploads to a different one:

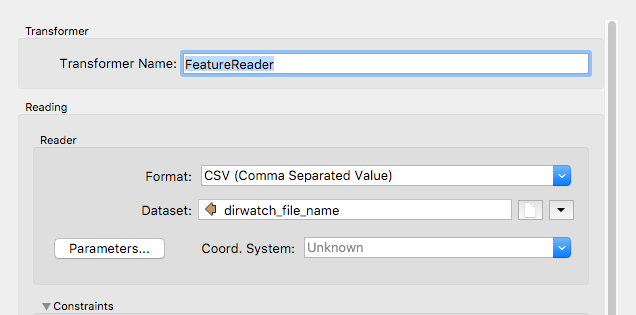
- FeatureReader reads in CSV file>Parse Media string and concatenation>Write to a "photo_ids.csv" file>FMEServerJobSubmitter inits next workspace below.
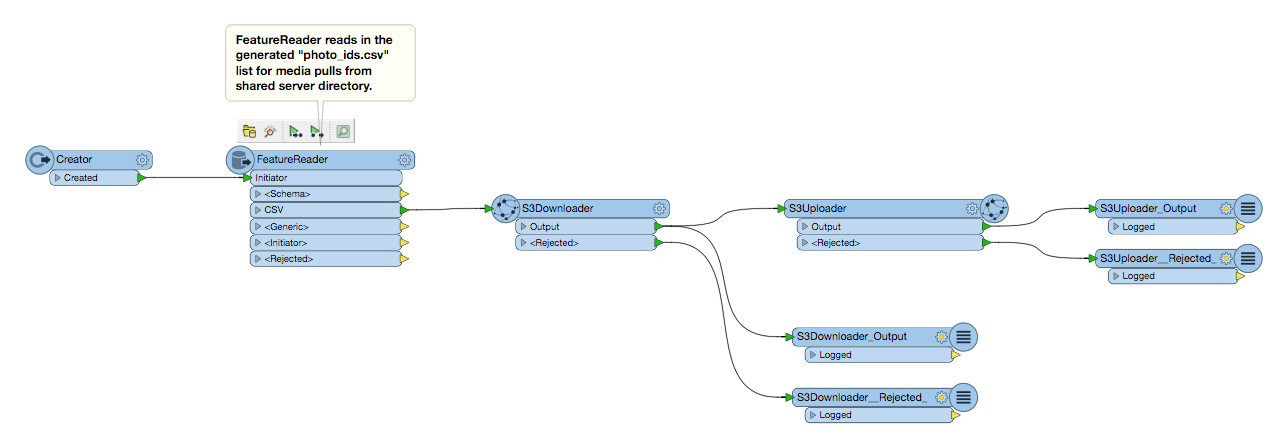
- FeatureReader reads in "photo_ids.csv" file>S3Downloader of media pull to server temp directory>S3Uploader to new bucket.
I could set up these jobs to run up to 23 separate workspaces and triggered based on each job having a unique directory watch trigger and compartmentalized directories for output. But I believe there is a better and more efficient way to perform this workflow, so I'm posting here to this community in hopes someone can recommend me with a better solution.
I'm just having trouble thinking it through clearly, since I'm fairly new to server notification services and using the generated log files to parse string text for multiple jobs completed and triggering downstream workspaces. Thanks in advance for any help provided to this rather long and complex question.