
Hi
can you hlep me to understand if I can extract info from this webpage
https://viabilita.autostrade.it/it/viabilita/previsioni
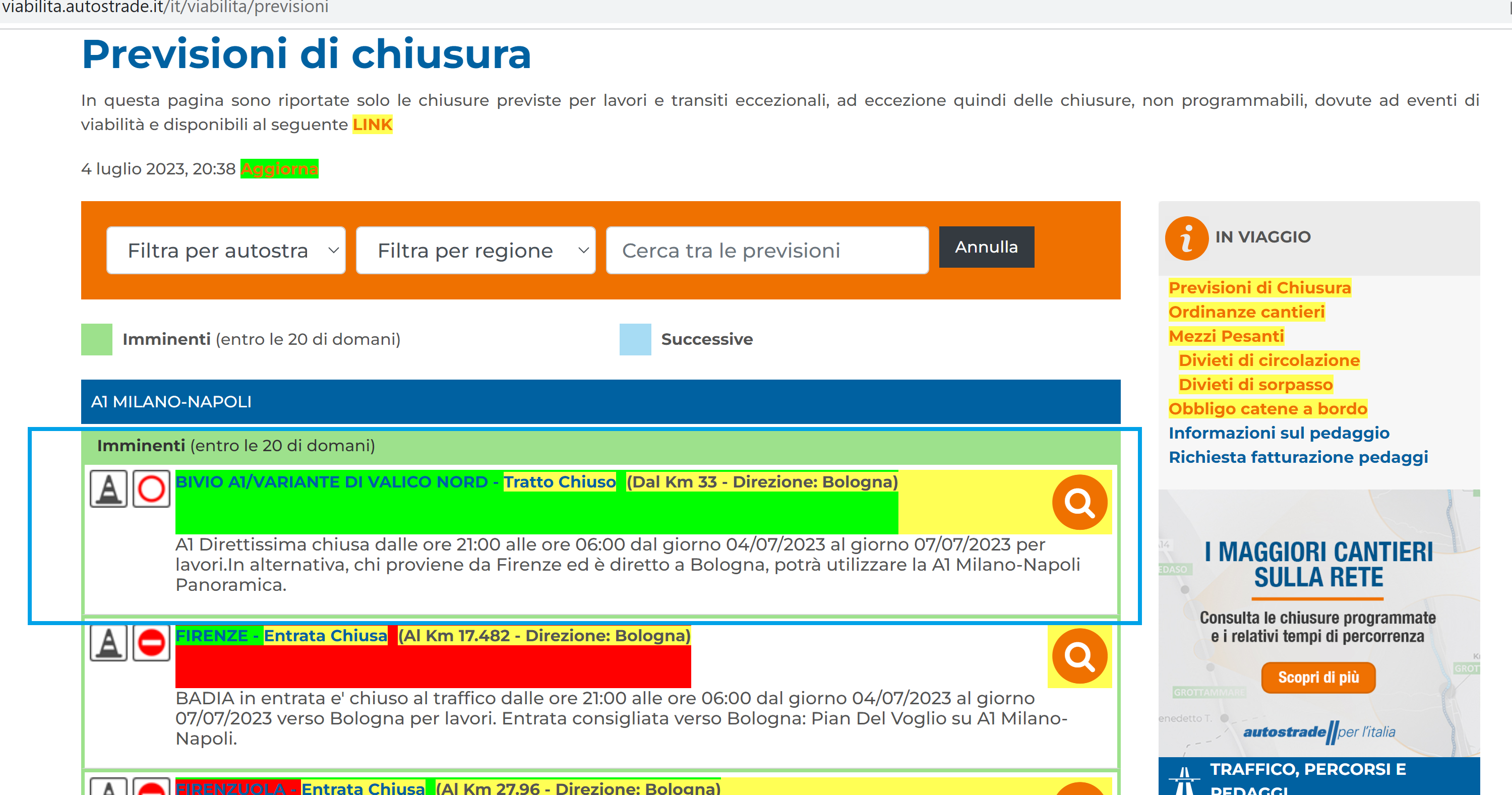
What I need is the info in the blue box
thx
Francesco

 +14
+14Hi
can you hlep me to understand if I can extract info from this webpage
https://viabilita.autostrade.it/it/viabilita/previsioni
What I need is the info in the blue box
thx
Francesco
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.



")
