Hi.
I'm trying to build a simple workspace that extracts logged features from a log file.
Since a logged feature in the log file is wrapped by a starter line and an end line, I'm using a variable to keep track of whether I'm inside a logged section or not.
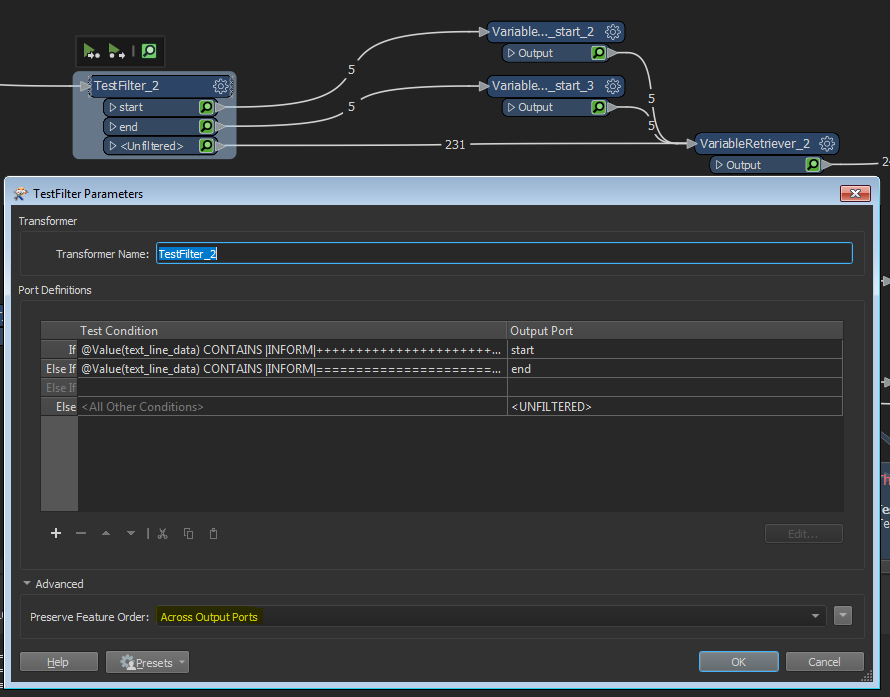
I'm reading the log file as a text file, and forking the read line feature 3-ways with connection order: (1) check for start line, (2) output if started, and (3) check for end line. In (1) and (3) I'm changing the variable to 1 or 0 resp., while in (2) I'm checking whether the retrieved variable value is 1 before doing an output.
Unfortunately it seems that my check in (2) is always true ??
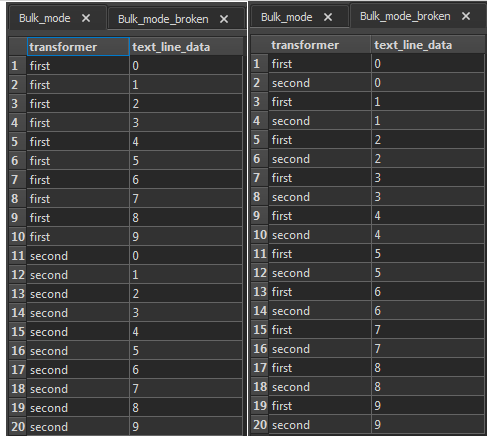
It looks like the FeatureReader is sending all line features into each connection, one by one, so first (1) receives all features, then (2) receives all features, etc.
I inserted a FeatureHolder immidiatedly after the FeatureReader, in case it was a problem with the reader, but it changed nothing.
As far as I understand, a single feature should be processed into all three connections before the next feature is processed. Is my understanding of this incorrect ?
Using 2020.0
Cheers.