Hello,
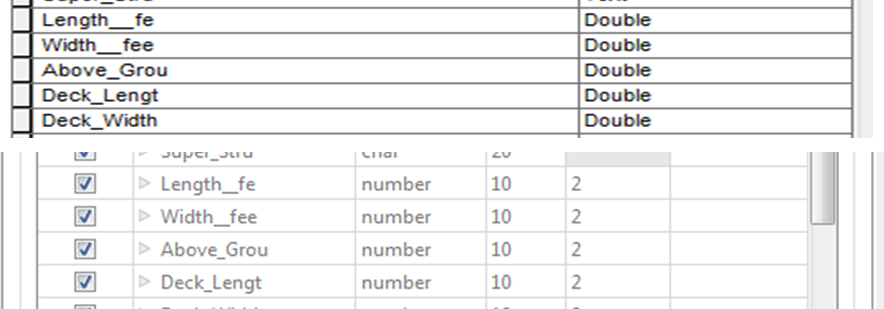
I have some data in Shape File format that when read into FME the field type changes from Double to an encoded attribute. See the below screen shots from both Arc Catalog and FME's reader transformer. Below is the printout from the log file. So my end goal is to use the "getAttributeType()" type method to perform some data renaming using the attribute type. So is there something I'm missing with the Shape File Reader or Shape File specification in FME?If I import the data into a File Geodatabase it works fine where FME will maintain the field types.
Attribute(encoded: fme-system): `Length__fe' has value `10'
Attribute(encoded: fme-system): `Width__fee' has value `3
FME Build information below:
FME Database Edition
FME 2017.1.0.0 Build 17488 - WIN32.
Any help or information as to why FME does this would be very helpful!