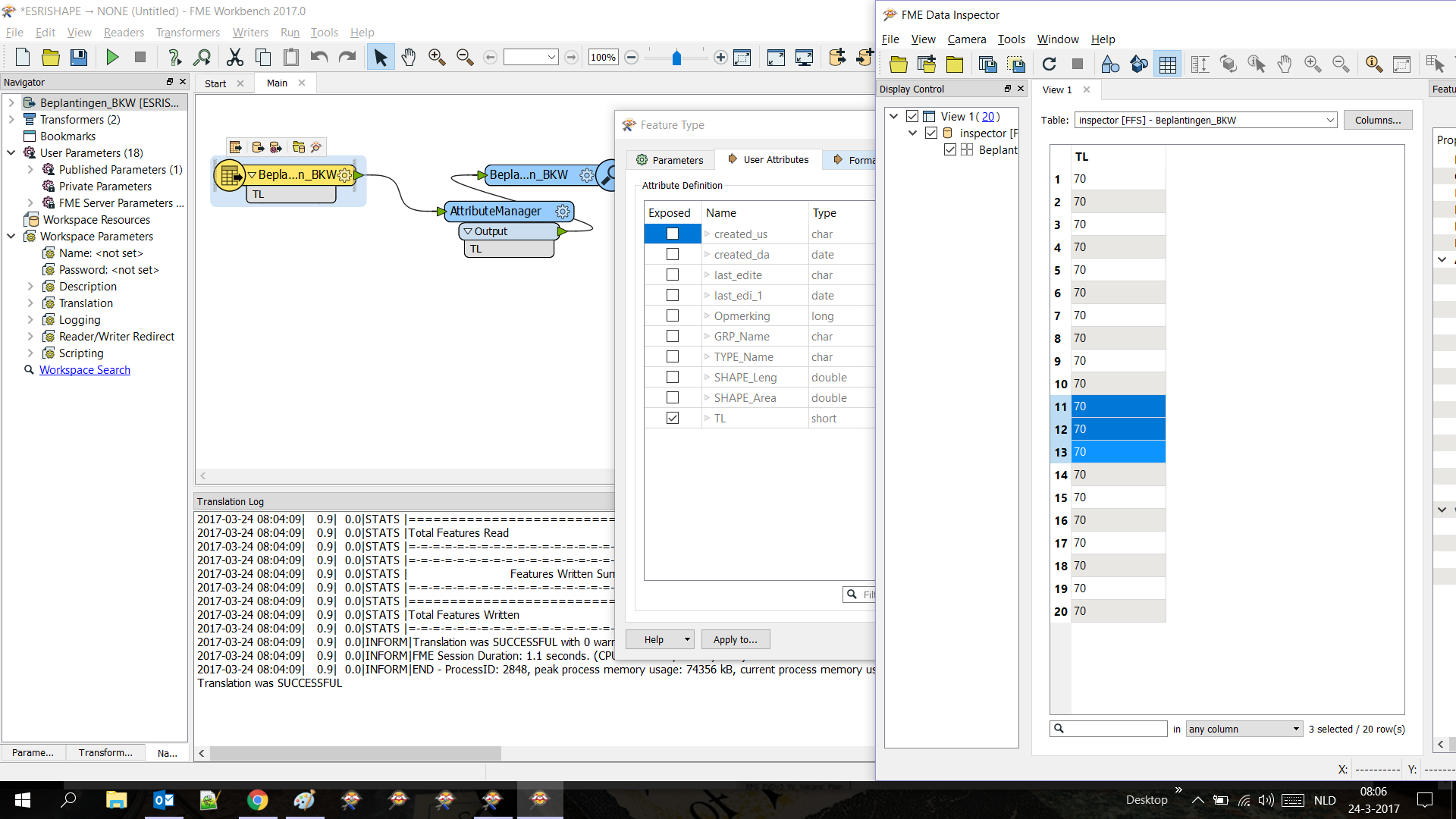
On the FME roadshow someone mentioned there was a way to remove attributes on the reader to improve performance. Unchecking attributes on the feature reader properties User Attributes just seems to hide them but reads these attributes anyway - eg. hidden attributes still appear in Data Inspector. See attached.

Solved
remove attributes on read
Best answer by takashi
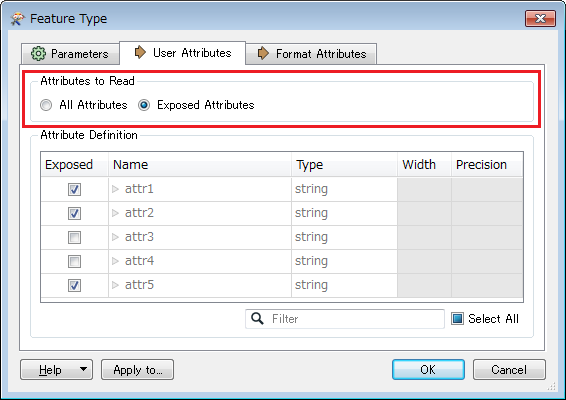
The functionality has been introduced in FME 2017.0 for some formats, not for all formats. The Attributes to Read options appear on the User Attributes tab in the reader feature type if the reader supports the functionality. e.g. [CSV reader feature type in FME 2017.0]
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.









Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.