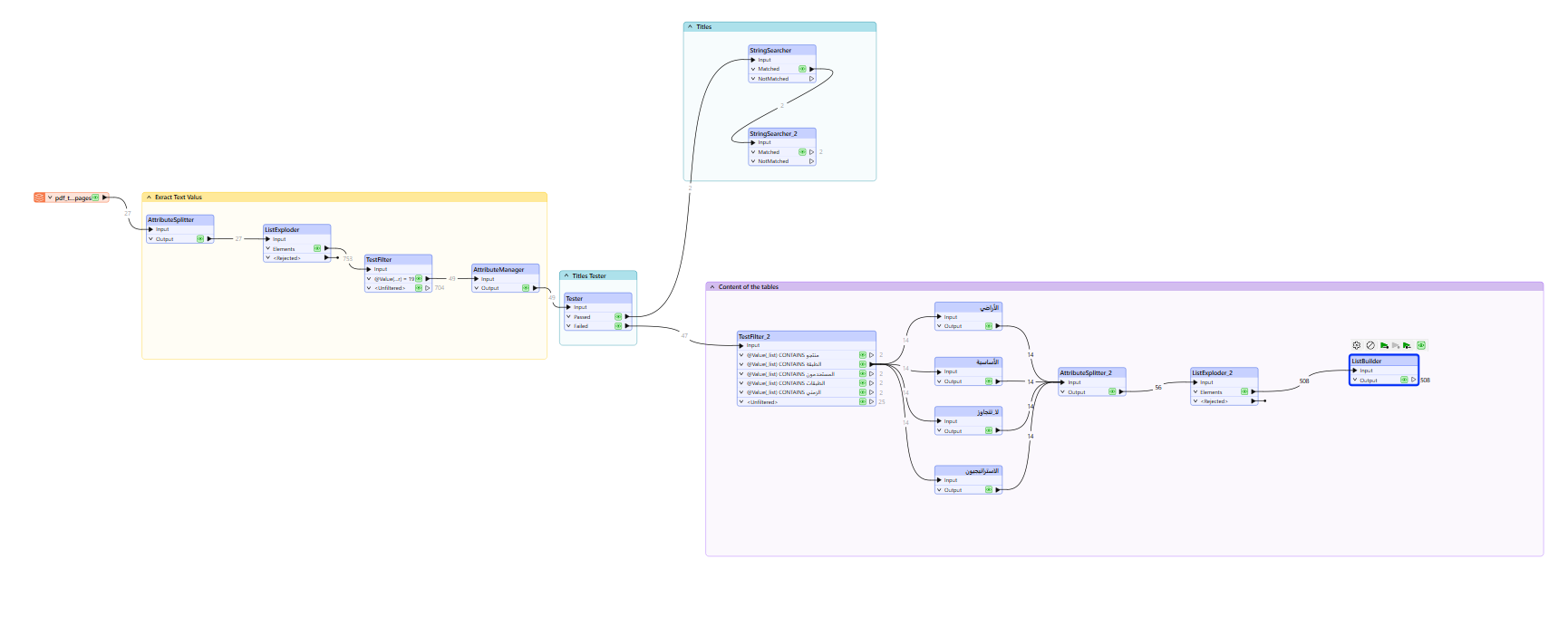
I’ve reached the workflow stage, but I can’t proceed further. I’m trying to extract multiple tables from a PDF file. I’ve been following https://support.safe.com/hc/en-us/articles/25407564475277-Extracting-Text-and-Tabular-Data-from-PDF#h_01HW3Z9Z37Q33NQQ7R0XBGEVB0, but the structure of my PDF is quite different.
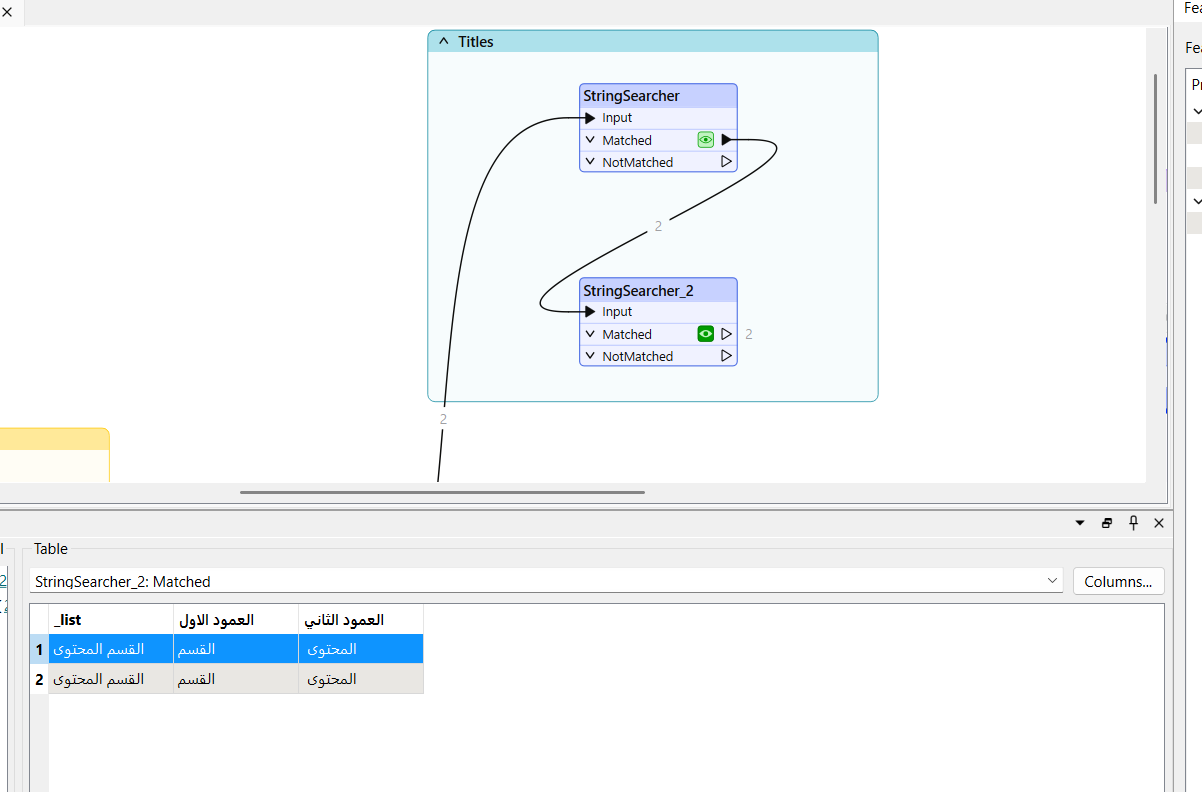
I only want to extract the tables—nothing else. In my case, the table has titles on the right and content on the left. I used the StringSearcher to extract the titles, since they are easier to identify (usually one word).
The challenge now is that I can’t extract or separate the content, as it’s made up of long sentences that are mixed with the titles. I'm looking for a solution to:
-
Separate the content from the titles
-
Structure the extracted data into table as the source data