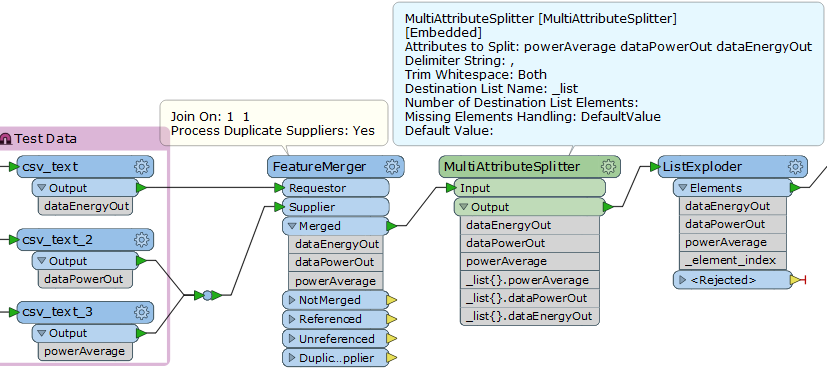
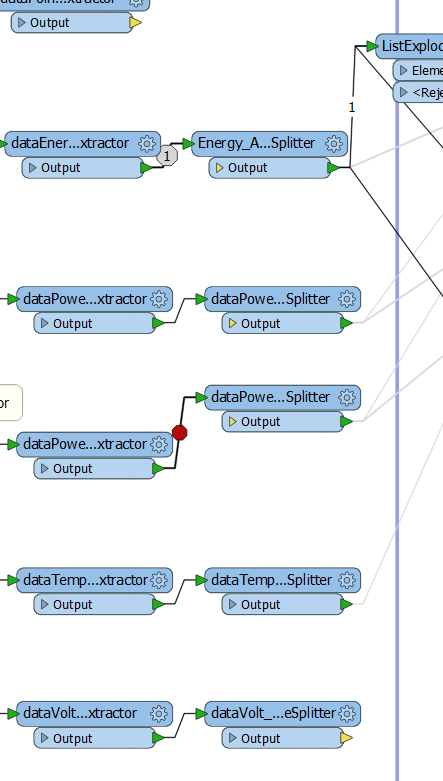
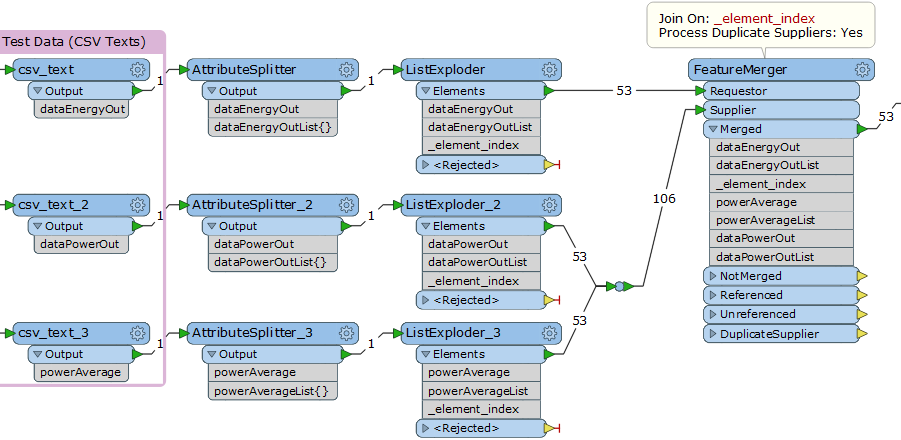
Hi,
I have a couple of lists with dynamic size (e.g. _energyList, _powerList, _timeList, etc...). I would like to merge these lists together in order to get them prepared for inserting them into the MySQL database.
At the moment, I get the lists merged together indeed but in a sequence, perhaps the snap shot below could make it clearer:
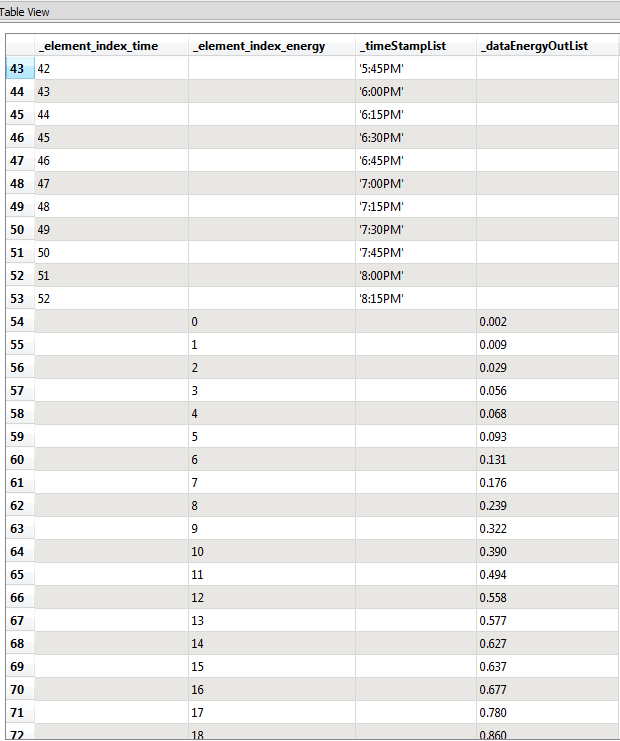
And of course this is not what I'm trying to do. I need to get the _timeStamp and the _dataEnergy, etc... at the same row.
One possibility could be, to use ListExploder to each of the lists and insert each one of the items into its relevant column in the database separately. But this doesn't seem to be the right approach.
The goal at the end, is to create a list that is ready to be inserted into a database table that looks like the following:

I checked the thread below but it didn't do the trick.
https://knowledge.safe.com/questions/24685/merge-list-on-index.html
Does anyone maybe have an idea on how to get it to work?
Thanks a lot!