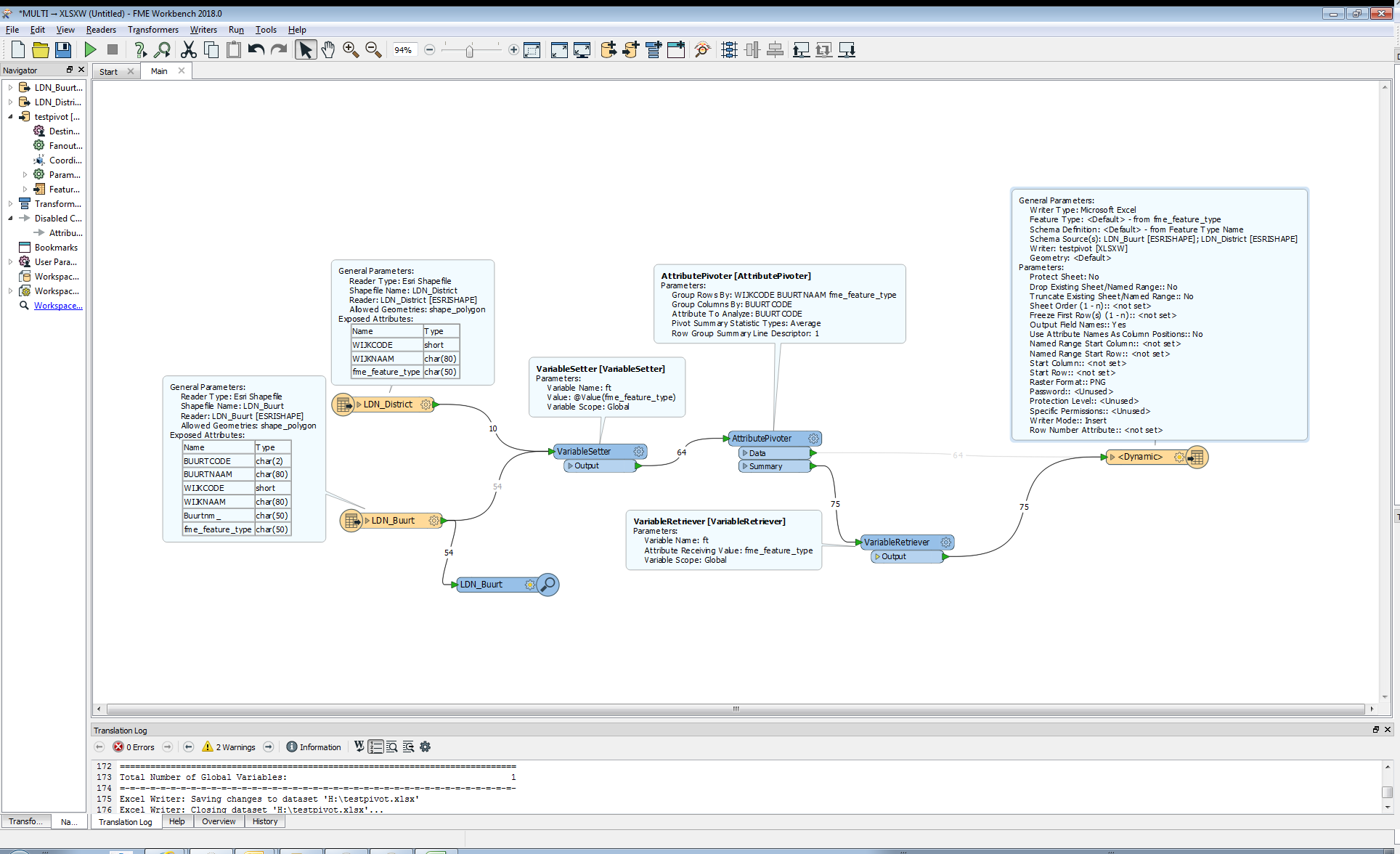
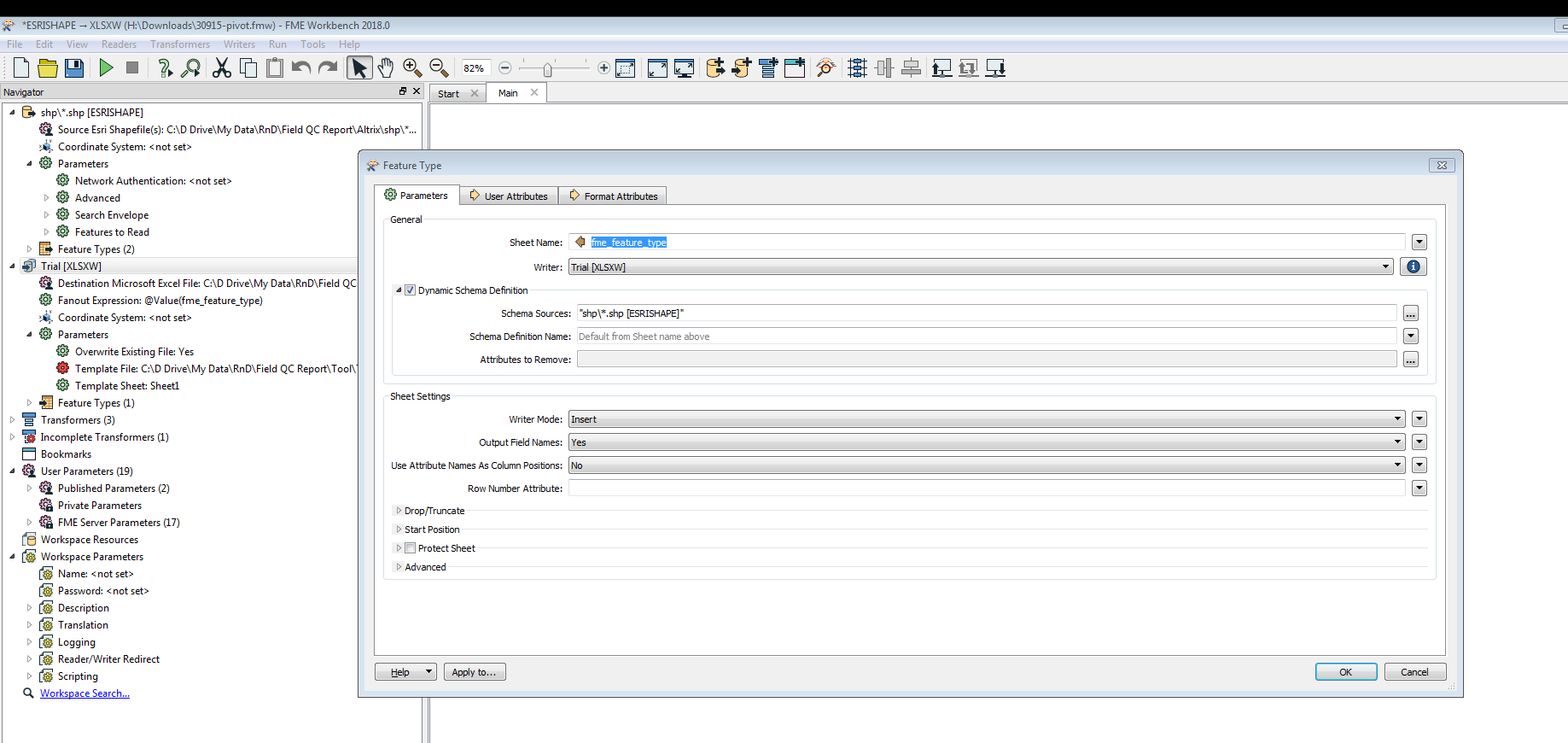
Hello,
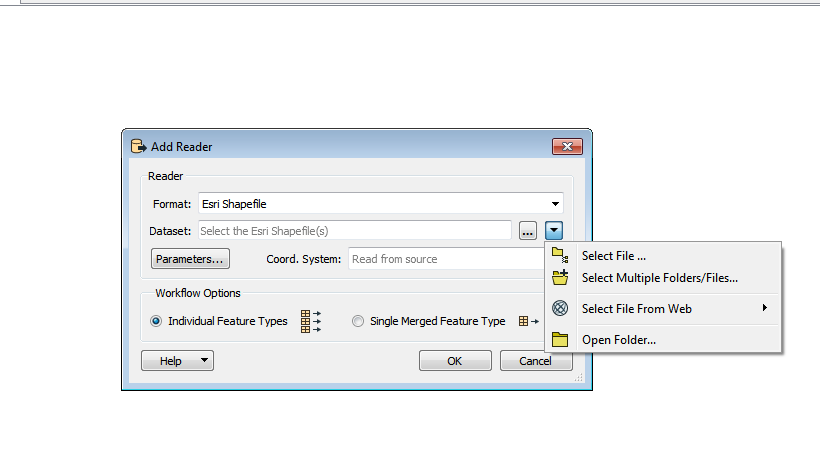
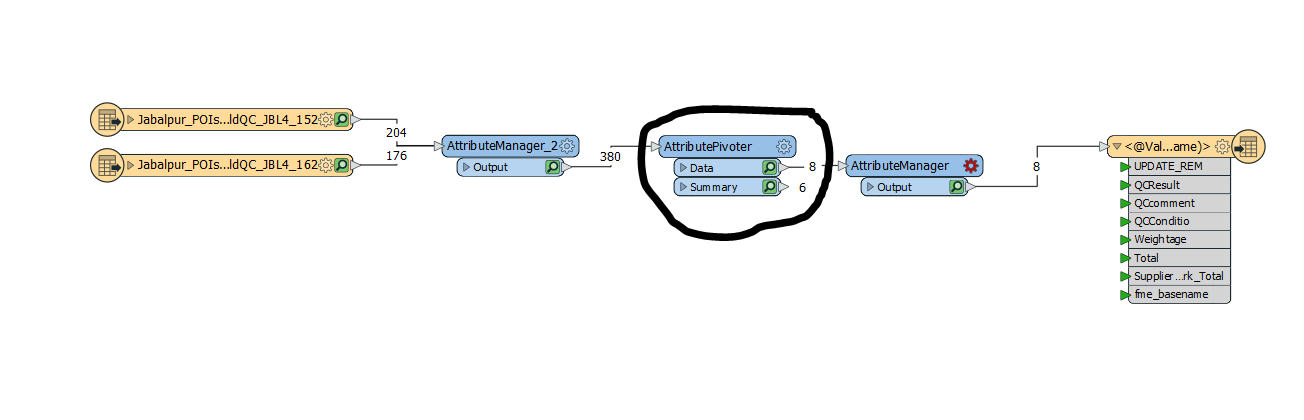
I have some shapefiles in a folder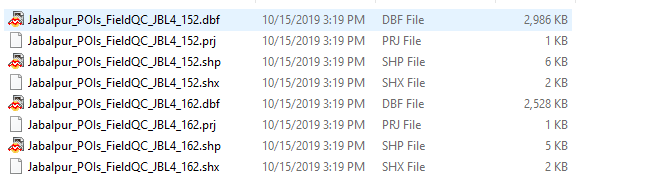 Is there any way the workbench does select all files one by one and do the processing. The workbench that i have designed works fine for one shapefile and gives me the output in Excel in sheet 1.
Is there any way the workbench does select all files one by one and do the processing. The workbench that i have designed works fine for one shapefile and gives me the output in Excel in sheet 1.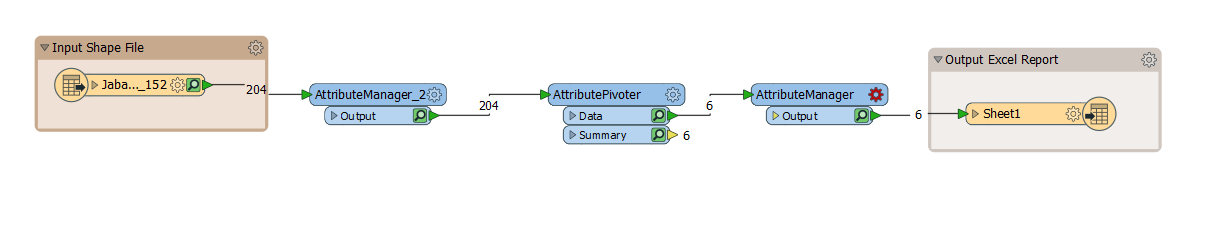
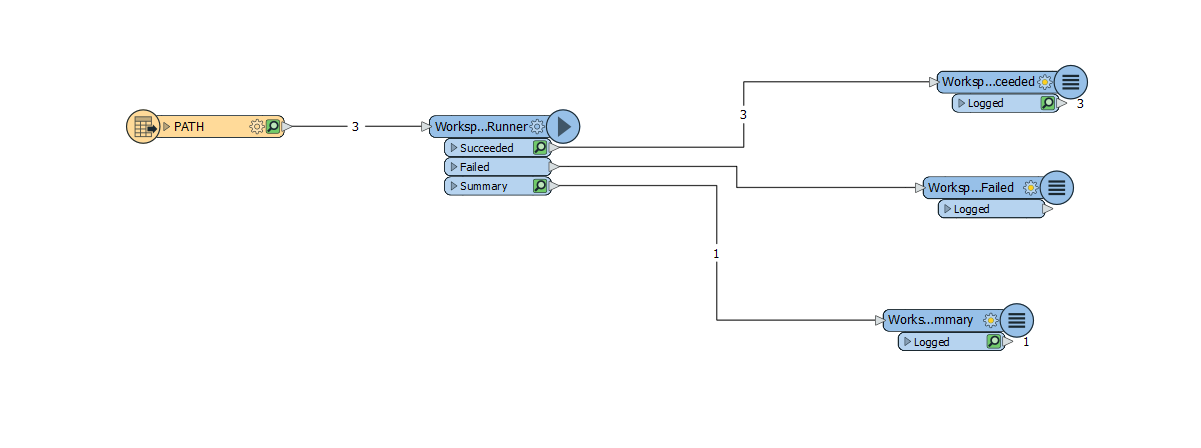
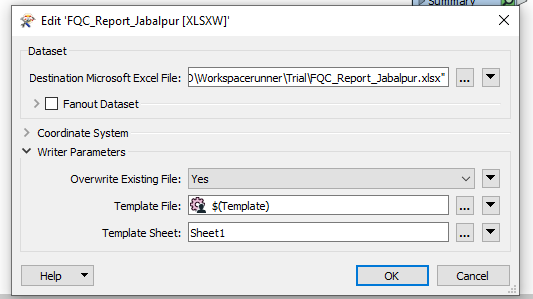
Also i have created a workspacerunner.This is not giving me the desired output. I need output of all the shapefiles in excel in different sheets respectively.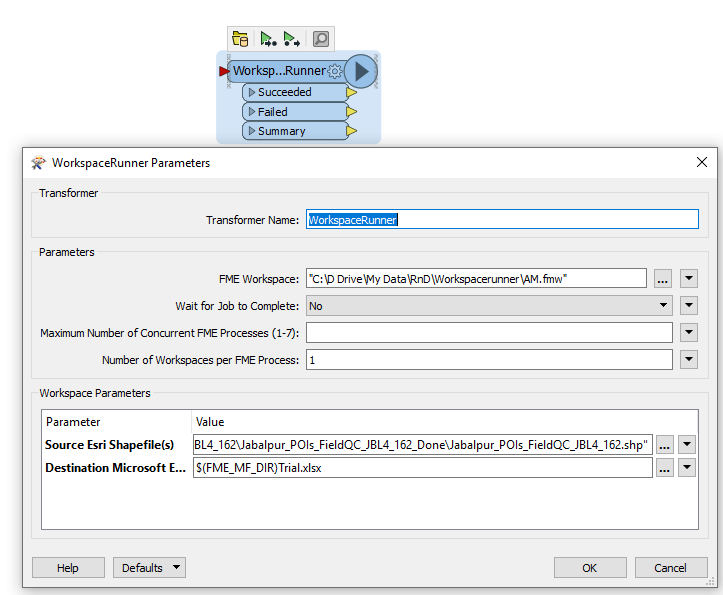
Any help is much appreciated.