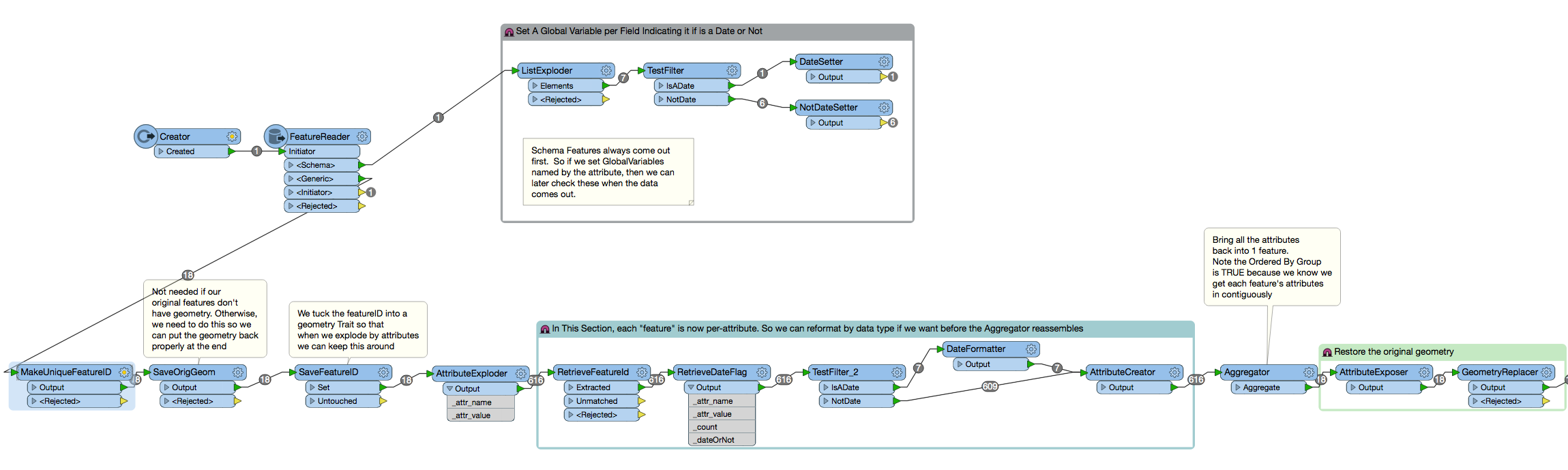
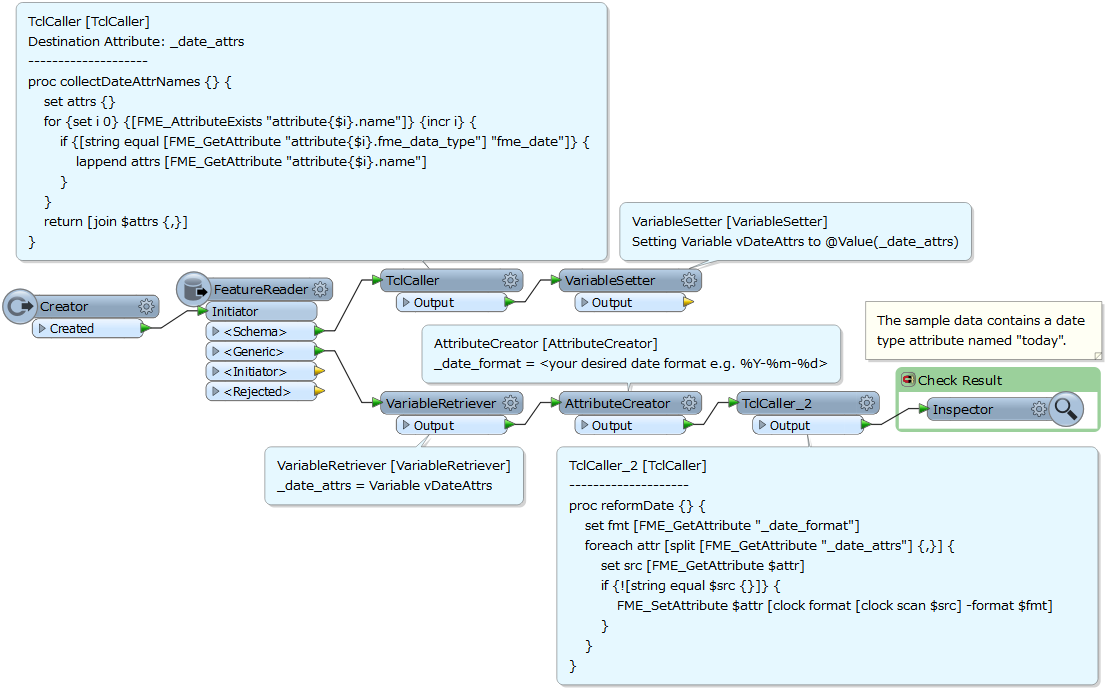
I have an issue where a dynamic workspace working with hundreds of data sets needs to be able to expose fields if they are DateTime. Due to the sheer number of datasets and fields I don't really wish to hard-code this into the workspace. I was hoping there was a way to expose fields when they are a particular datatype, in this case DateTime. The reason that I need to expose them is due to json not having the ability to write out DateTime fields correctly, they need to be converted to strings using the dateformatter. The workspace is dynamic and may open hundreds of datatypes depending on the parameters coming in. I don't want to have to hard code but I am thinking I might need to expose all the relevant fields within the FeatureReader, I am using FME 2015.1.
The date formater works fine but the attributes must be exposed to be able to select them within the transformer.
Thanks in advance!