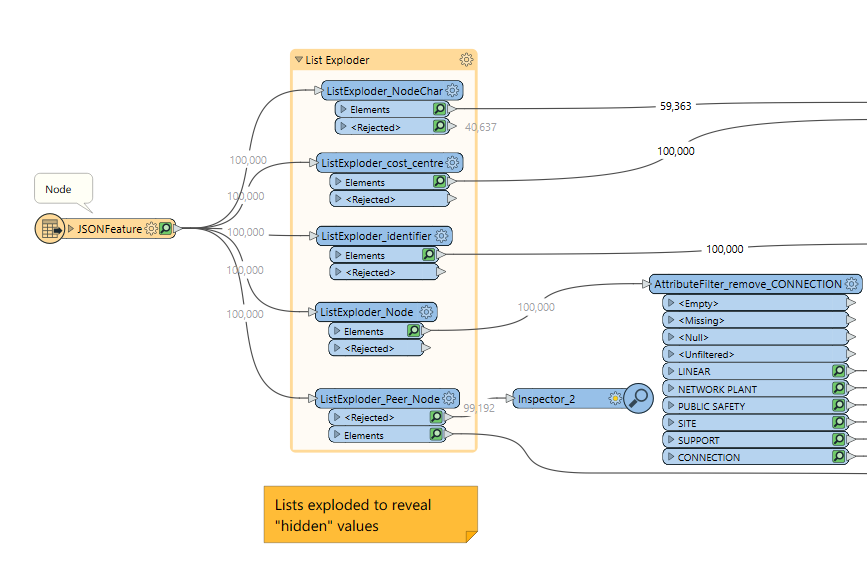
I have a json file with lots of attributes hidden in lists. So I use 5 ListExploders to expose those attributes.
The ultimate goal is to then combine all of those attribute fields into one massive table, using the unique identifier field of “NODE_ID”.
As you can see in the screenshot the Node list then feeds into AttributeFilter to reduce the number of features a little.
So far so good… but this is where it goes a bit mad.
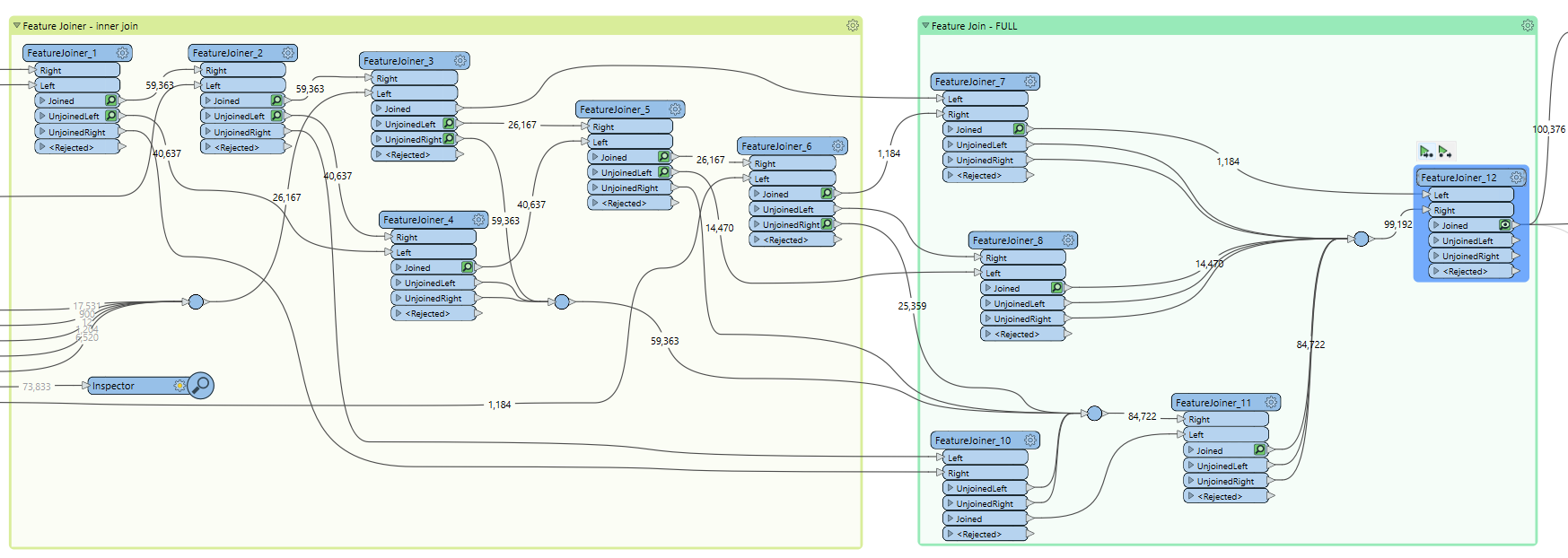
I then need to combine all of those 5 exposed lists into one table. FeatureJoiners are then used to try to merge the datasets together.
Those in the left hand bookmark are joined using an inner join to try to get as many features with the same NODE_ID value combined into the same row in the table.
Those in the right hand bookmark then use a full join to pick up any stragglers from the first bookmark.
I have 200 JSON files to work on, and this example uses just one of them, so I have to try to account for all output ports, to ensure nothing is left behind, hence why some connector lines have zero features in them.
I now have 12 FeatureJoiners and it looks like the work of a madman!
Surely there is a better way of working than this!? Is there another transformer that can join multiple data streams together? FeatureJoiner works great when combining just 2 streams, but I have 5.
If anyone thinks that what I’ve done is actually ok then please do let me know!
Much indebted to any of you with any good ideas.
Stu
Best answer by stu_home
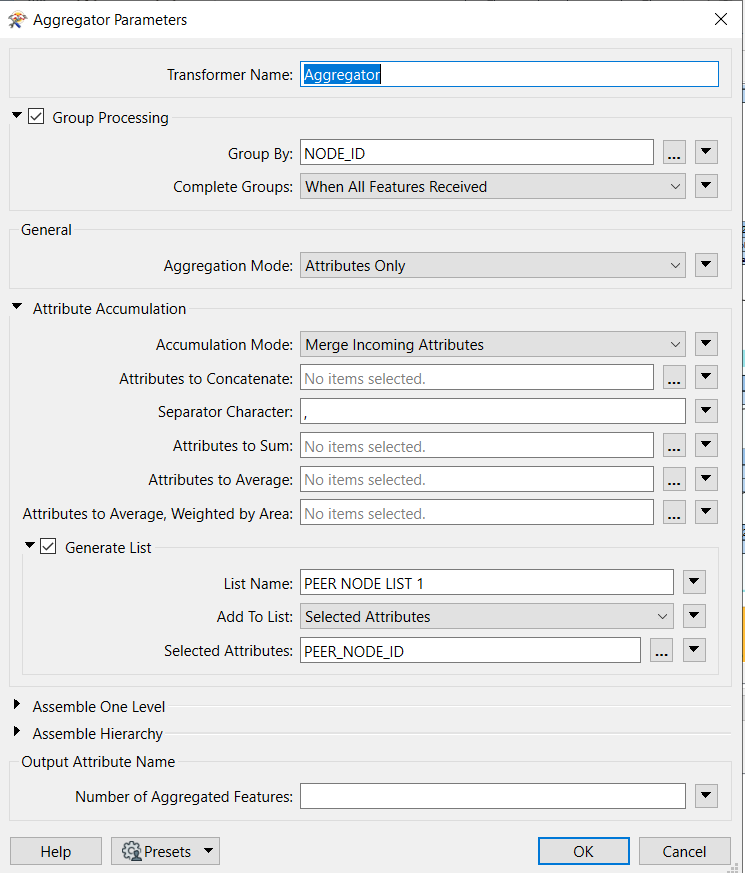
Last time I had a similar usecase I created an unique ID (GUIDGenerator) and then exploded all lists with the ListExploder. After some othe operations/transformer i merged them all together with the Aggregator, Grouped By the unique ID. Did you tried this already?
BTW: Use the Accumulation Mode: Merge Incoming Attributes
Thanks for this suggestion Thomas. The Aggregator is a great tool, however, from my 5 exploded lists there will sometimes be multiple entries of the NODE_ID, only one per list, but it could be that particular NODE_ID is featured in multiple lists. Each list has it’s own exclusive columns / attribute fields, so I want to combine all of these into one big table. Where a NODE_ID occurs in more than one list I want to create one line in the table, and add those exclusive columns to the table with the values, of course. So where there is no clash of attribute value (ie on one list there’s a value for a particular column, but the next list the value in that column is null / missing etc) it merges them nicely into one row. But where there is a case where there is a value in that column from both lists the Aggregator overwrites one of the values, whereas I would rather there be two entries for that NODE_ID (ie create a duplicate) to show both of those values, each in a separate row. When I bring them together in Aggregator it merges the multiple NODE_ID into one line, and where I have duplicates from different lists I lose some data during the merge, which I do not want. I want to preserve all of the data. Does that make sense?
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
There are transformers that can help you with this, like JSONExtractor, JSONFlattener, and JSONFragmenter. They take some getting used to though, parsing JSON can be somewhat of a challenge.
There are transformers that can help you with this, like JSONExtractor, JSONFlattener, and JSONFragmenter. They take some getting used to though, parsing JSON can be somewhat of a challenge.
Thank you geomancer, yes, I presumed using the transformers you suggest would be the best methodology for extracting the JSON data, but I got absolutely nowhere with it. I couldn’t get any data out without it all entering the rejected port. I posted a question on here about it a couple of weeks ago and it was suggested I use the ListExploder and that worked. I’ve just had another look at it, and the json file is a .gz file. I have extracted it (in Windows) and now I can run it into the JSONExtractor! OK, I will work on this solution.
Last time I had a similar usecase I created an unique ID (GUIDGenerator) and then exploded all lists with the ListExploder. After some othe operations/transformer i merged them all together with the Aggregator, Grouped By the unique ID. Did you tried this already?
BTW: Use the Accumulation Mode: Merge Incoming Attributes
Last time I had a similar usecase I created an unique ID (GUIDGenerator) and then exploded all lists with the ListExploder. After some othe operations/transformer i merged them all together with the Aggregator, Grouped By the unique ID. Did you tried this already?
BTW: Use the Accumulation Mode: Merge Incoming Attributes
Thanks for this suggestion Thomas. The Aggregator is a great tool, however, from my 5 exploded lists there will sometimes be multiple entries of the NODE_ID, only one per list, but it could be that particular NODE_ID is featured in multiple lists. Each list has it’s own exclusive columns / attribute fields, so I want to combine all of these into one big table. Where a NODE_ID occurs in more than one list I want to create one line in the table, and add those exclusive columns to the table with the values, of course. So where there is no clash of attribute value (ie on one list there’s a value for a particular column, but the next list the value in that column is null / missing etc) it merges them nicely into one row. But where there is a case where there is a value in that column from both lists the Aggregator overwrites one of the values, whereas I would rather there be two entries for that NODE_ID (ie create a duplicate) to show both of those values, each in a separate row. When I bring them together in Aggregator it merges the multiple NODE_ID into one line, and where I have duplicates from different lists I lose some data during the merge, which I do not want. I want to preserve all of the data. Does that make sense?
Last time I had a similar usecase I created an unique ID (GUIDGenerator) and then exploded all lists with the ListExploder. After some othe operations/transformer i merged them all together with the Aggregator, Grouped By the unique ID. Did you tried this already?
BTW: Use the Accumulation Mode: Merge Incoming Attributes
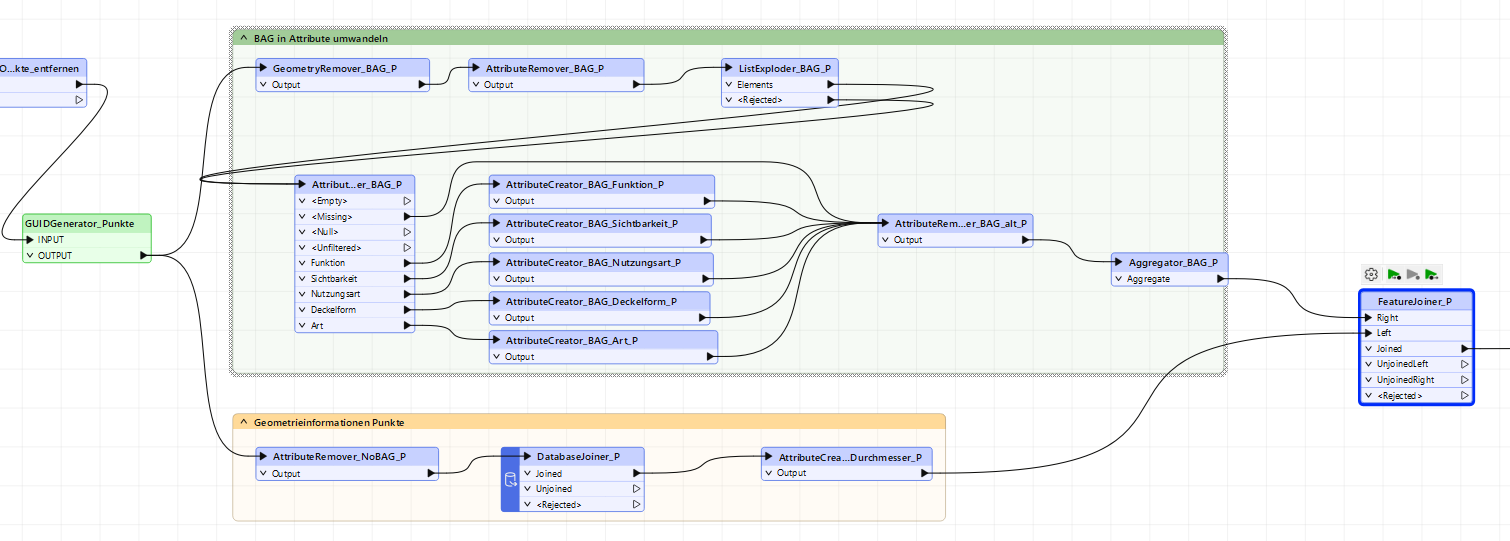
Thomas - I worked on this yesterday, and the trick for me was to use the Aggregator as per your suggestion, and to also generate a list based on the attribute field that produces the duplicates, PEER NODE. I then explode that list and join it all up using a single FeatureJoiner. This is now a really slick workbench. Many thanks for your suggestion.
Last time I had a similar usecase I created an unique ID (GUIDGenerator) and then exploded all lists with the ListExploder. After some othe operations/transformer i merged them all together with the Aggregator, Grouped By the unique ID. Did you tried this already?
BTW: Use the Accumulation Mode: Merge Incoming Attributes
Thomas - I worked on this yesterday, and the trick for me was to use the Aggregator as per your suggestion, and to also generate a list based on the attribute field that produces the duplicates, PEER NODE. I then explode that list and join it all up using a single FeatureJoiner. This is now a really slick workbench. Many thanks for your suggestion.