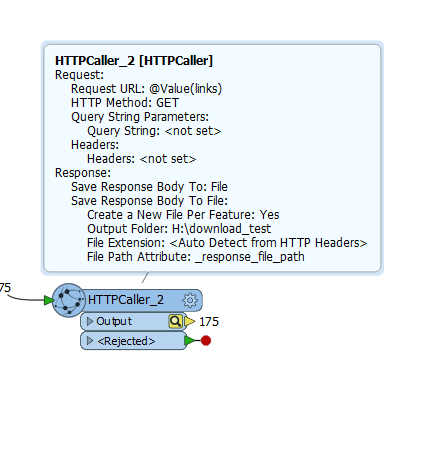
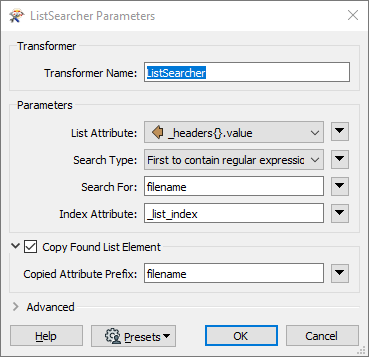
I'm using the HTTPCaller to download PDF documents to a set destination folder. The files get saved with the following name structure: "http_download_1582786318570_11140". This is not the same name I get when downloading the documents manually in a browser. I need the documents to be saved with the same name I get when doing it manually. Example: "Askholmen_SE0220343". Is it possible?
(URL to PDF-documents are found under the heading "Bevarandeplaner kommunvis")
HTTPCaller: