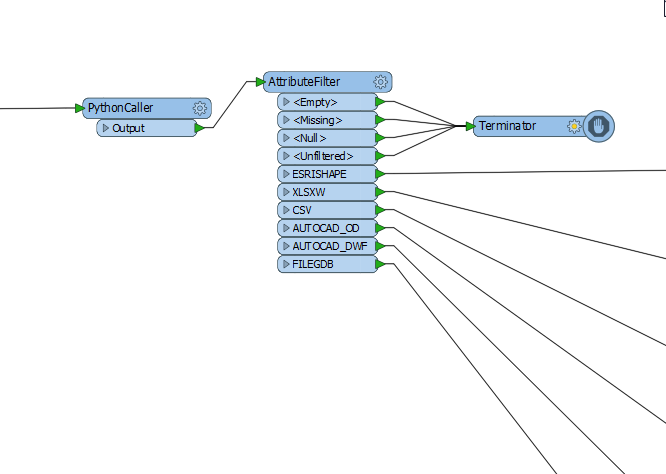
user selects one feature class (published parameter) and fme writes to one to six formats(like csv, shape, dgn, acad, xls,mapinfo etc...)
in the fmw i am asking formats to write via published parameter
output_format =dwg,shape, xls like(comma separated)
then i used python prg to split these values create new attribute for each format(yes)
import fme
import fmeobjects
import math
def frq(feature):
my_list = feature.getAttribute('_list{}')
ESRISHAPE=''
XLSXW=''
CSV=''
AUTOCAD_OD=''
AUTOCAD_DWF=''
FILEGDB=''
for item in my_list:
if item=="ESRISHAPE":
ESRISHAPE="YES"
if item=="FILEGDB":
FILEGDB="YES"
if item=="XLSXW":
XLSXW="YES"
if item=="CSV":
CSV="YES"
if item=="AUTOCAD_OD":
AUTOCAD_OD="YES"
if item=="DWF":
AUTOCAD_DWF="YES"
feature.setAttribute("ESRISHAPE", ESRISHAPE)
feature.setAttribute("XLSXW", XLSXW)
feature.setAttribute("CSV", CSV)
feature.setAttribute("AUTOCAD_OD", AUTOCAD_OD)
feature.setAttribute("AUTOCAD_DWF", AUTOCAD_DWF)
feature.setAttribute("FILEGDB", FILEGDB)
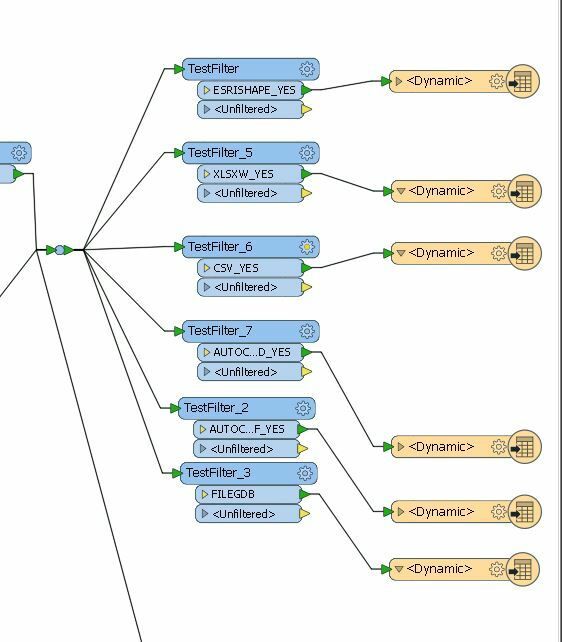
at the end i am checking these values using multiple test filters and sending to each writes
now my question is
if user wants to write 3 formats then all the features are going to each test filter transformers(6 filters for six formats)
dwg=yes then goes to dwg writer
dgn = yes then goes to dgn writer
........
........
all the features goes to 6 diffrent feature filter for testing the attrib value
i think , we can write same fmw in more optimized way? my worry is , if i have to write only three formats then why all the features should go to six filters ? this is the huge load for fme right?
can we do something for the optimization?