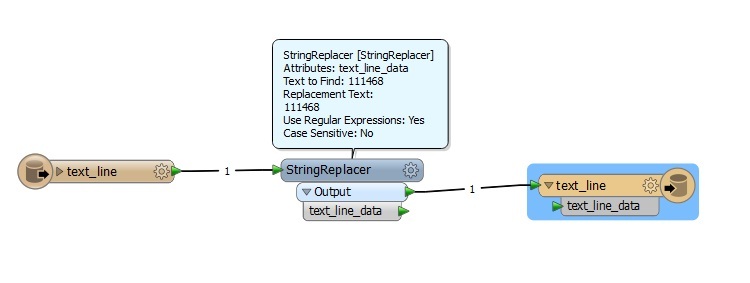
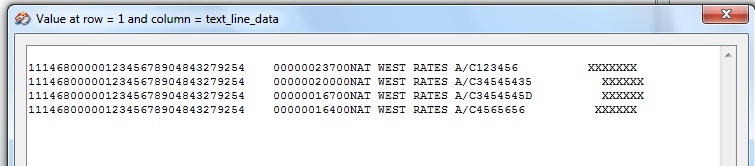
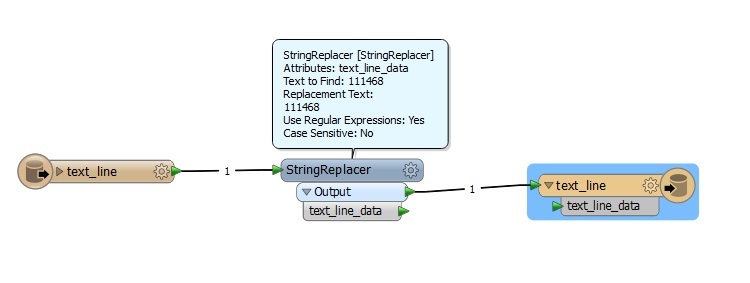
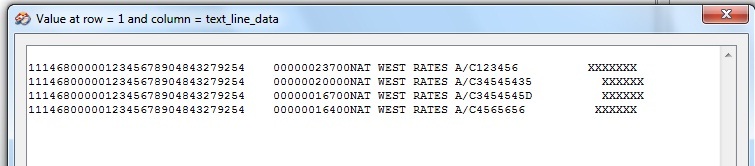
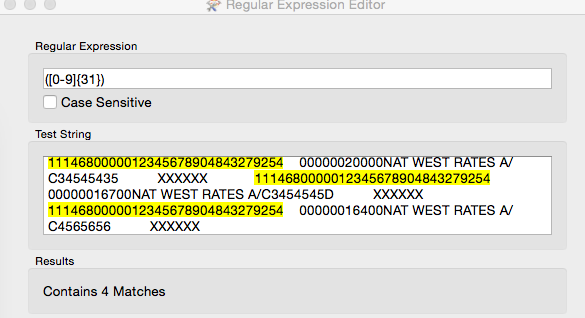
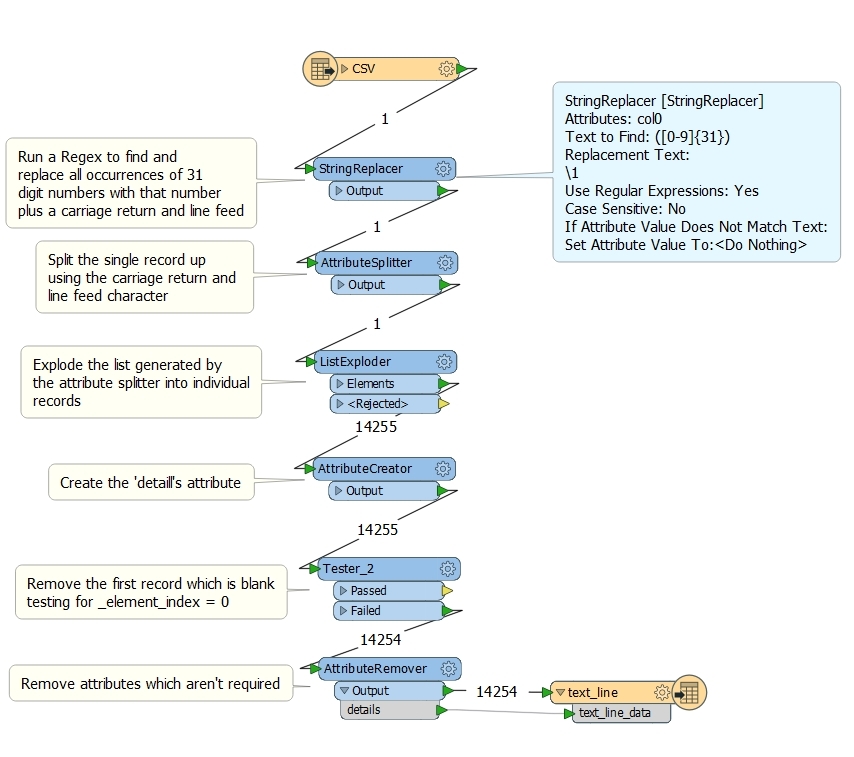
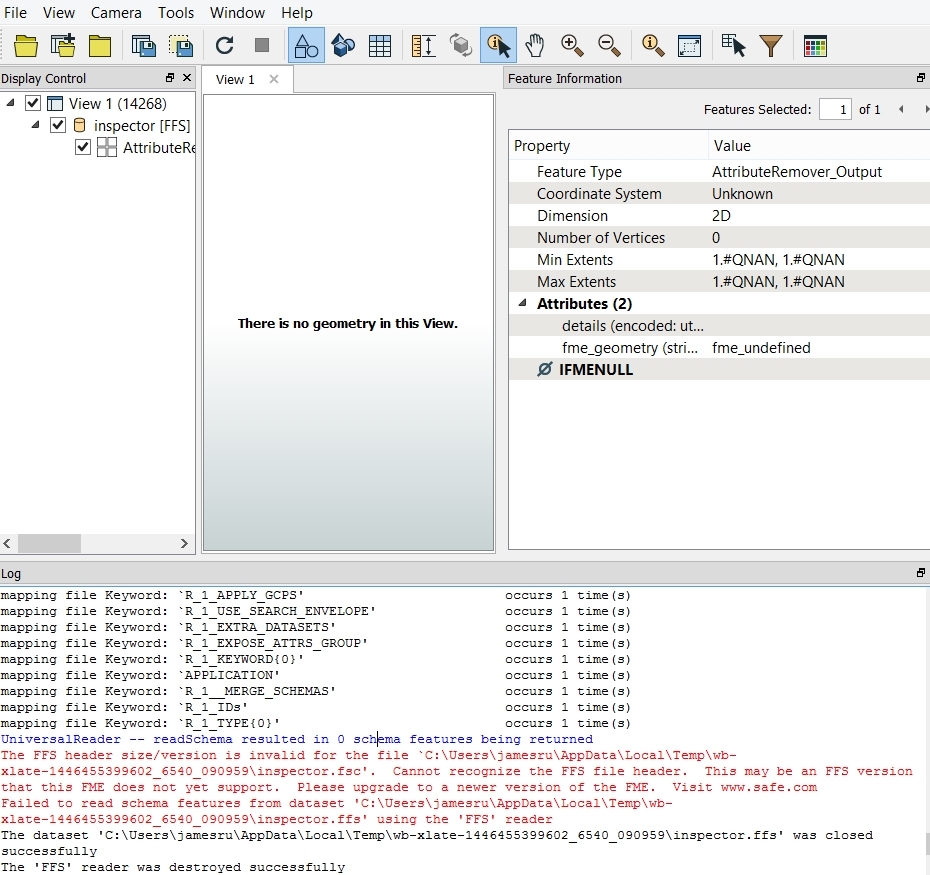
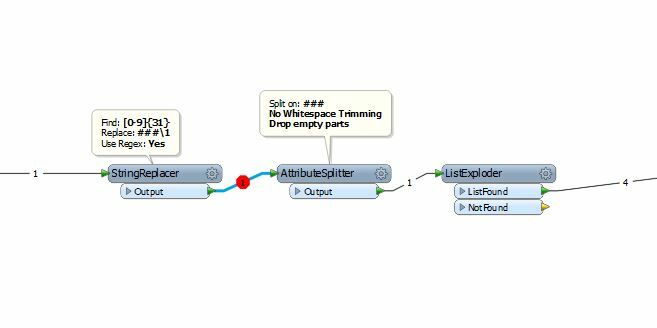
I have a large text file produced on a Unix system containing bank records for around 27,000 entries. The sample file attached shows a small snippet of how the file is structured - which is all on a single line. Each entry contains a 31 digit number. In a text editor I simply do a regex search for [0-9]{31} and replace the matches with the matched text plus a line feed character in front of it. Thus the text file gets restructured as per the screen dump with one record per line.
Is there a way of achieving this in FME? The regex stuff seems a bit clunky. I worked out that the stringsearcher transformer will only pick up the first occurrence of a match. A transformer from the Store is available called RegularExpressionMatcher is available which finds all occurrences and sticks them into a list. Where I go from there is what I could do with some help with please.

Thanks
James