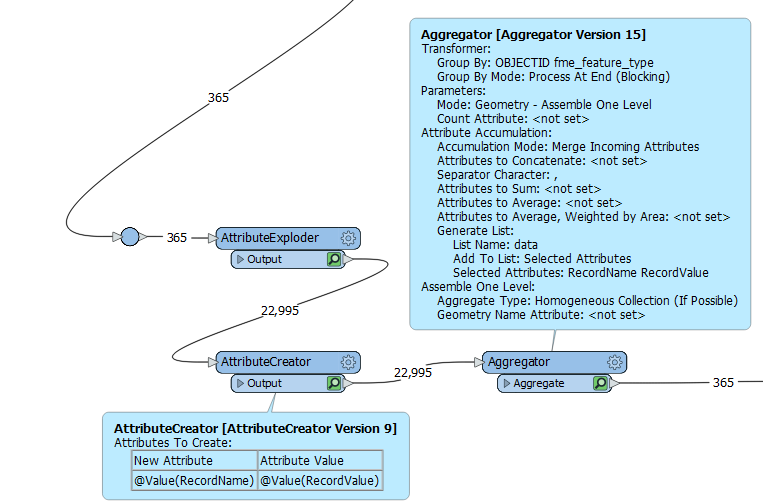
I have several custom transformers which perform different QA checks. They are designed to read in any data set with any number of tables and columns per table and perform checks for each table.
Within this custom transformer, I run the data through an AttributeExploder and have the following:
attr_name | attr_value.
I do a few tricks to attach fme format attributes to each value | name pair to get the following:
DatasetName | DatasetType | TableName | RecordName | RecordValue
Below is a screenshot of an example of some data for just two tables:
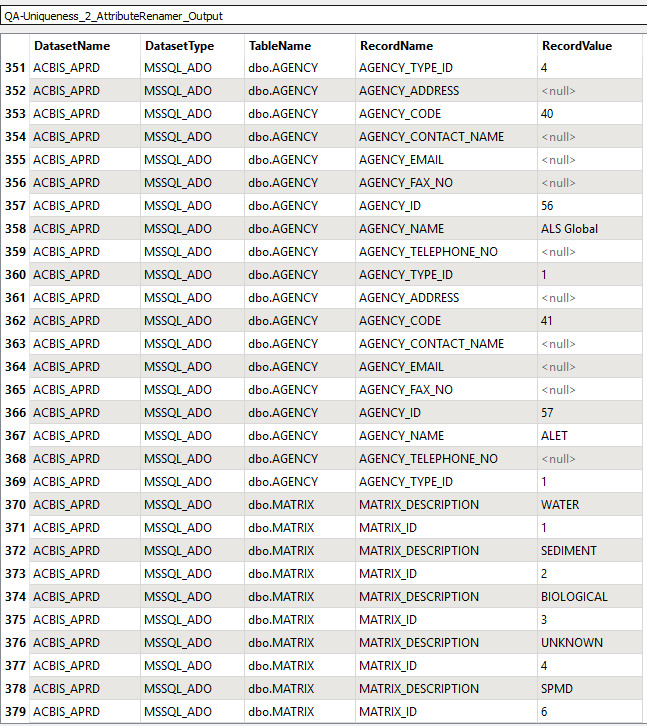
So what I want to do is split out the data into their original tables, pivot, and perform analysis on each one - simply find any rows with repeating data - ALL WITHIN THE CURRENT CUSTOM TRANSFORMER - without having to write to file and read in again etc..
For Example:
TableNameMATRIX_IDMATRIX_DESCRIPTIONdbo.MATRIX6SPMDdbo.MATRIX4UNKNOWNdbo.MATRIX3BIOLOGICALdbo.MATRIX2SEDIMENTdbo.MATRIX1WATER
Using a couple of Aggregators, I was able to get the data formatted as follows

This way there is a 3D array (List) of the data that could possibly be restructured using python...
I wrote a bit of pseudocode that has the general idea:
#Loop through the 3D List to build the individual tables:
For i = 0 to data.length
for j = 0 to data[i].RecordValues.Length
##Create New Feature:
Feature = new Feature()
Feature.attribute[j].name = data[i].RecordName
Feature.attribute[j].value = data[i].RecordValue[j].RecordValue
However,
a) i dont know if FME can create new features like that
b) Not sure how the different tables would be split apart.
c) The Lists length tend to be the total length of the table with the most columns (attributes) so those with shorter lengths tend to have the same amount of attributes as the largest ones all filled in with nulls.
I've been stuck on this for a while. I hope someone has insight on how I might be able to make this happen.
-Dave B