")

Hi, I asked about comparing the attributes of two datasets which have same attribute table earlier, and @DanAtSafe helped me out. But now I have a lot datasets to compare and they don't have same attribute table, which means every time I have to create a new comparing workbench, that's a lot work and I may miss some attributes or set the wrong parameters.
So I'm thinking about creating a custom transformer to iterate coming feature's attributes. I've been looking into help documents about Looping, but it seems that's not possible to get the count of the incoming attribues, not to mention iterate them. ListElementCounter will only come back with the count of the list, not the attributes in the list.
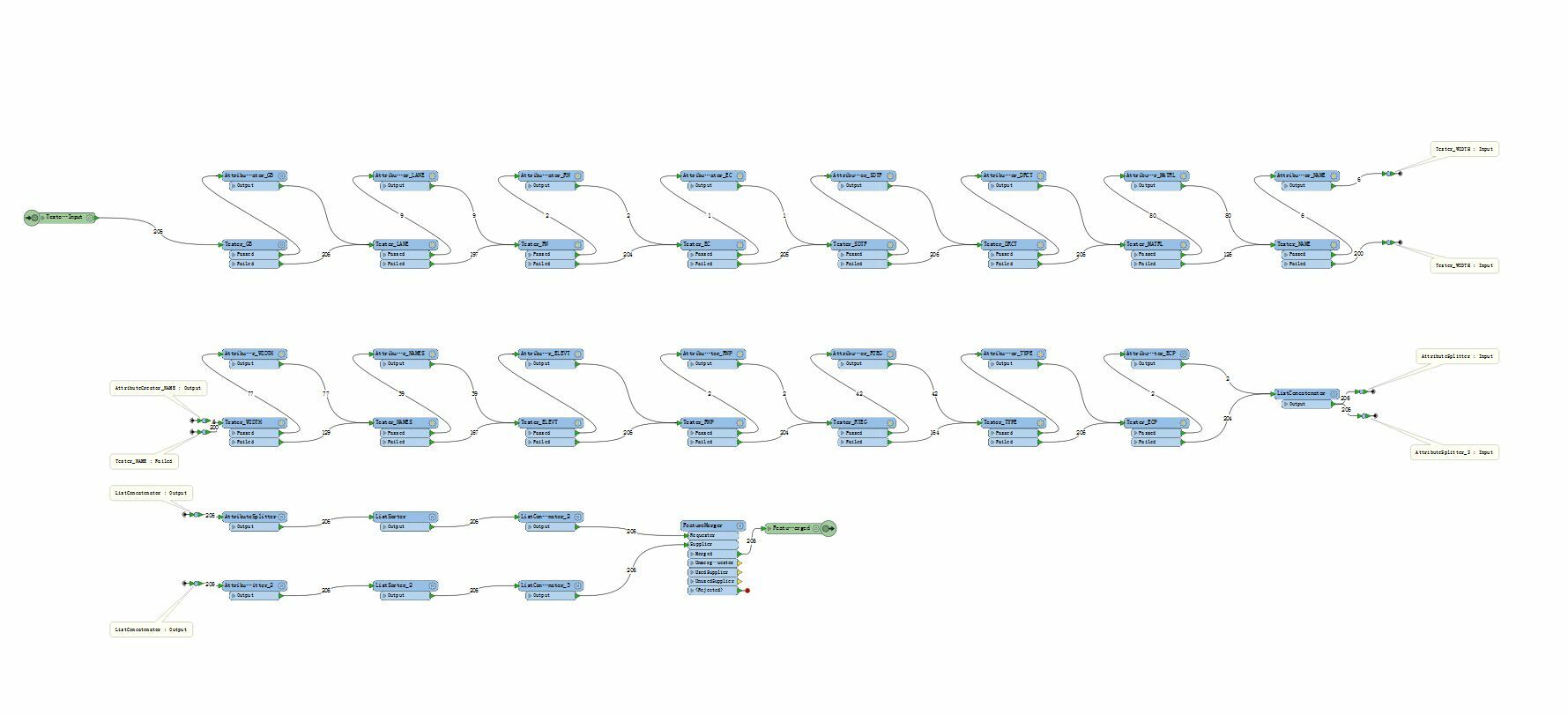
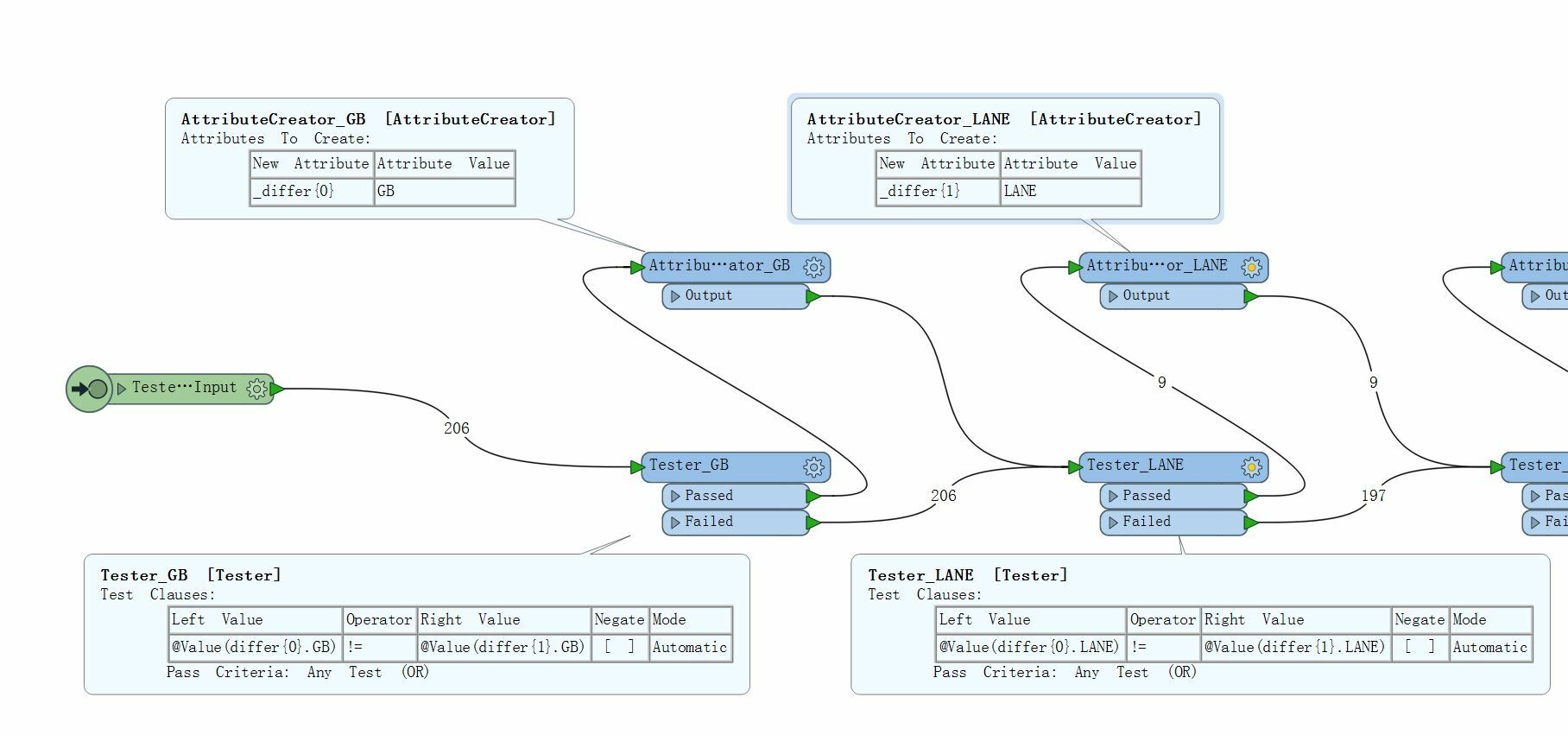
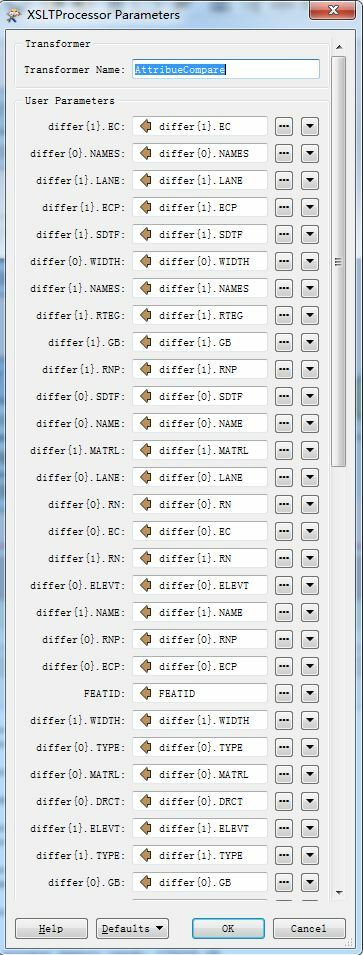
Figure1 below is the whole workbench I created based on Dan's method, Figure2 below is the part of workbench with summary annotation, and Figure3 is all the input attributes of a pair of datasets, I want to compare all attributes in the differ{} list.
I'm not sure FuzzyStringComparer would work or not, and there're too many versions of them.
Please help me out, I don't want to go the old fashion way, thank you guys.
@takashi @Mark2AtSafe @MarkAtSafe @DanAtSafe @jdh