I have a question regarding the implementation of dynamic attributes.
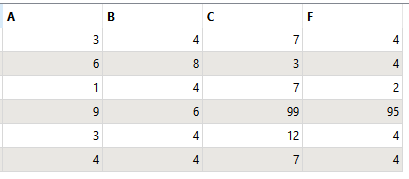
I created a flow to turn a single attribute into text for the actual values of the column and row of an attribute;
Following the pattern below:
Original AttributeGoal
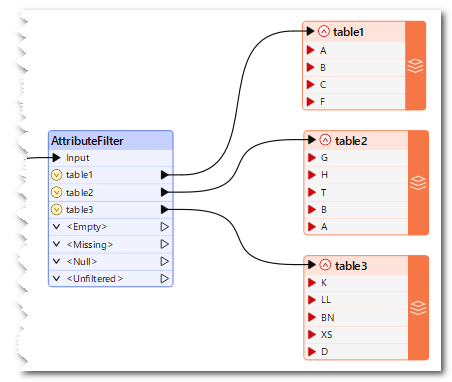
After achieving this, the biggest problem is that these 'dynamic' name attributes come as unexposed attributes.
Unexposed Attributes
I could simply place an AttributeExposer and resolve this case, but the problem is that the flow will run in several different scenarios, and the values (A, B, C, F) will never be the same; they can vary to anything (G, H, T, Z, B, A, or K, LL, BN, XS, D).
Therefore, I need the exposer to work automatically as well, but I couldn't make it receive @value(list_name); it literally exposes the value '@value(list_name)' as if it were an attribute with the name of the code.
Thank you for your assistance!
Best regards,
Best answer by takashi
If the destination table schemas are already defined, you can add writer feature types (tables) with appropriate User Attributes configuration for each schema to the workspace, and just send features to matched feature type after extracting individual attributes. No need to expose the extracted attribute names on Workbench interface.
The workflow looks like this, assuming that you can add an attribute storing destination schema (table) name to the input features.
See also the attached workspace example.
[Addition]
Alternatively, you can apply a dynamic workflow method as @hkingsbury mentioned. I think this method would be suitable if the destination tables exist in the database already.
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
Unfortunately there is no way to automatically expose attributes which will be created at run time.
Why do you need to expose the attributes? Depending on the case, exposing attributes could not be essential to achieve your goal..
I have a PostGIS database that already has defined schemas for each type of feature I intend to import. Each feature contains specific attributes, with some potentially sharing columns while others are completely distinct.
The data I am processing comes from an external source, and upon analyzing it, I noticed that the attribute values are consolidated into a single field. After separating these attributes, my goal is to import them into the appropriate schemas.
If the destination table schemas are already defined, you can add writer feature types (tables) with appropriate User Attributes configuration for each schema to the workspace, and just send features to matched feature type after extracting individual attributes. No need to expose the extracted attribute names on Workbench interface.
The workflow looks like this, assuming that you can add an attribute storing destination schema (table) name to the input features.
See also the attached workspace example.
[Addition]
Alternatively, you can apply a dynamic workflow method as @hkingsbury mentioned. I think this method would be suitable if the destination tables exist in the database already.