

I have a JSON file, structured like this:
{
"W-Number": {
"EP1": [
{
"timestamp": 1407859200000,
"value": 1.35
},
{
"timestamp": 1407862800000,
"value": 1.44
}
],
"EP2": [
{
"timestamp": 1407859200000,
"value": 1.58
},
{
"timestamp": 1407862800000,
"value": 1.63
}
]
}
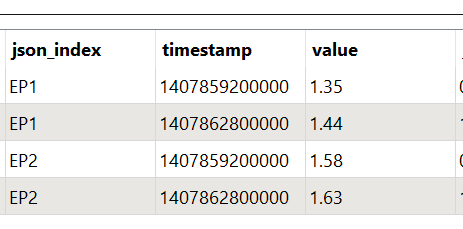
}I want to turn it into a table, like this
W-Number | timestamp | value
EP1 | 1407859200000 | 1.35
EP1 | 1407862800000 | 1.44
EP2 | 1407859200000 | 1.58
EP2 | 1407862800000 | 1.63What I managed so far: used JSONFlattener, then AttributeExposer to expose (see below*). Then I used a ListExploder; it works when I specify e.g. W-Number-EP1{}, which gives me a table for the timestamp and value of EP1, however I require a single Table for all EP's that might exist, without exploding the list for each manually. Would that be possible somehow?
*
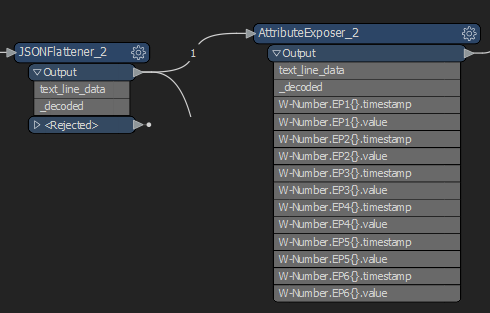
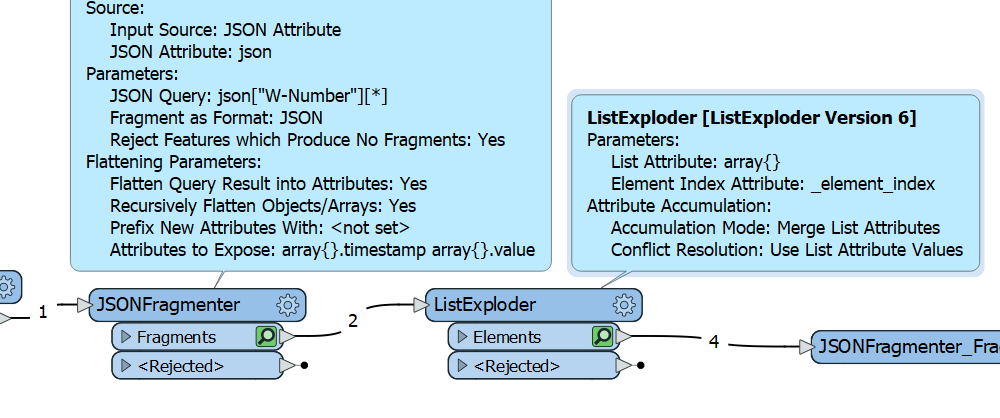


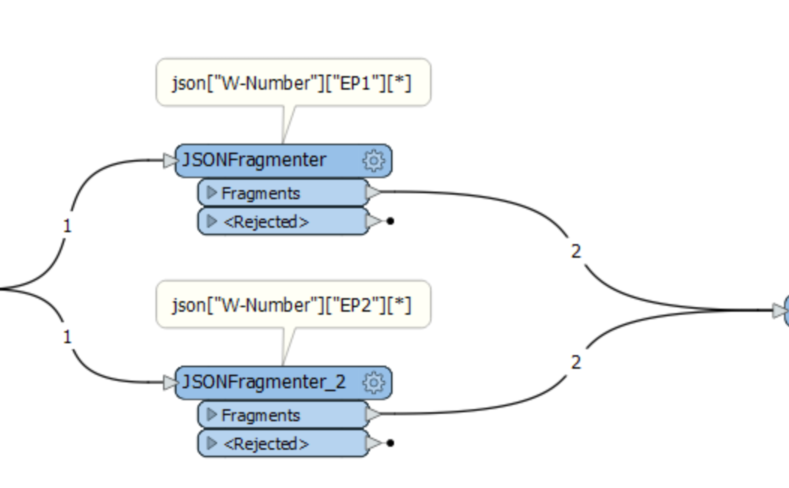 You'll maybe want to add e.g. an AttributeCreator after each JSONFragmenter to identify if each line is from EP1 or EP2.
You'll maybe want to add e.g. an AttributeCreator after each JSONFragmenter to identify if each line is from EP1 or EP2.




