I have a dataset of features that I'm trying to insert in a Postgres (pg14) database. That data has a number of text columns that together make up a "report name" plus a timestamp. The name and timestamp together make up the primary key of that dataset. There are also some more columns that contain the actual data. The table I'm inserting this in currently has 800 million rows, and I'm inserting in batches of around 50k rows about a hundred times a day, so keeping indexes small is important.
Given the above situation, the text columns from the "report name" have been put into a separate "dataset_reports" table" (~60k rows); with the timestamp and actual data being stored separately (with a foreign index) in their own heavily partitionned "dataset_reports_data" (~800M rows) table. In order to insert data in that table, I need to upsert dataset_reports with all the unique report names in my feature set in a first pass, then get the FK value for all these reports and then I can insert the actual data in "dataset_reports_data".
To try and reduce back and forth, what I used to do (before FME) was to bulk copy all the data I was going to insert in a temporary table, and then have the database handle all the deduplication and joining. Something like this:
-- STEP 1: Create a session-private and session-scoped temporary table CREATE TEMPORARY TABLE _tmp_dataset_full_data ( report_name_a text NOT NULL, report_name_b text NOT NULL, line_timestamp timestamptz NOT NULL, rest_of_the_data text NOT NULL );
-- STEP 2: Copy everything to the DB for easy manipulation COPY TO _tmp_dataset_full_data ;
-- STEP 3: Fill the report names table -- report_id is generated by a sequence column INSERT INTO dataset_reports (report_name_a, report_name_b) ( SELECT DISTINCT report_name_a, report_name_b FROM _tmp_dataset_full_data ) ON CONFLICT (report_name_a, report_name_b) DO NOTHING ;
-- STEP 4: Fill the data table by joining to get the possibly new report_id INSERT INTO dataset_report_data (report_id,line_timestamp,rest_of_the_data) ( SELECT report_id,line_timestamp,rest_of_the_data FROM _tmp_dataset_full_data AS report_lines INNER JOIN dataset_reports AS reports USING (report_name_a,report_name_b) ) ON CONFLICT (report_id, line_timestamp) DO NOTHING ;
I can easily use the "Run before/after write" queries to take care of steps 1, 3 and 4, even though I'm sure that's not what they were intended for.
My problem is that FME's Postgres Writer needs a schema-qualified table to work, and will check to see that said table exists prior to inserting, and that part is currently failing with "POSTGRES Writer: Table 'public._tmp_dataset_full_data' does not exist. Please check the Table Name specified, or modify the Table Handling value under Format Parameters".
The query FME uses to test for the table's existence (this is copied from the database's statement log) looks like this:
select tablename from pg_tables where schemaname = 'pg_temp' and tablename = '_tmp_dataset_full_data'
-
This seems to make step 2 impossible, because Postgres' temporary tables don't live in a fixed schema, but in pg_temp,, which is an alias to a per-session private schema that's actually named something like "pg_temp_102", is unique for every session, and should be tested like this.
select tablename from pg_tables where schemaname::regnamespace = pg_my_temp_schema() and tablename = '_tmp_dataset_full_data';
So is there a way with FME (I'm currently on 2022.1) to make the Writer understand that this is a temporary table that does exist, or perhaps to skip the check entirely and go straight to inserting?
I'm very new to FME, so I realize that this may not be the "idiomatic" way of doing things.
Best answer by vlroyrenn
Ok, so I've accepted that this isn't currently possible under FME 2022 or 2023, so I've had to make do with something else.
The use of temporary tables in PostgreSQL would mean that the tables are not logged to the WAL, are deleted after insertion and don't have any risk of collision if multiple instances of a script try creating the same table at the same time.
The first two, you can achieve with an unlogged table and a DROP TABLE in the "After SQL" hook. The third one is trickier, since there's not really any kind of "unique run ID" that I could find in FME documentation, so I've taken to creating my own by imitating TempPathnameCreator. This has to be done as a scripted user parameter, because reading this from attributes makes things even more needlessly complicated.
# User parameter: UNIQUE_RUN_ID
# Configuring a logger to catch scripted parameter errors import logging logging.basicConfig(filename=r'D:\FME\fme_param_log.log', encoding='utf-8', level=logging.DEBUG, force=True)
#print(unique_run_id) return unique_run_id except: logging.exception("Error in parameter UNIQUE_RUN_ID") raise return
Furthermore, we need a database schema to store these temporary tables, where users are allowed to create tables but not interfere with the tables of other users, and still be able to delete them:
CREATE SCHEMA IF NOT EXISTS fme_fake_pg_temp AUTHORIZATION postgres;
GRANT CREATE ON SCHEMA fme_fake_pg_temp TO PUBLIC;
COMMENT ON SCHEMA fme_fake_pg_temp IS 'PUBLIC is not granted the USAGE privilieve, so users can only access the tables they own/have created.';
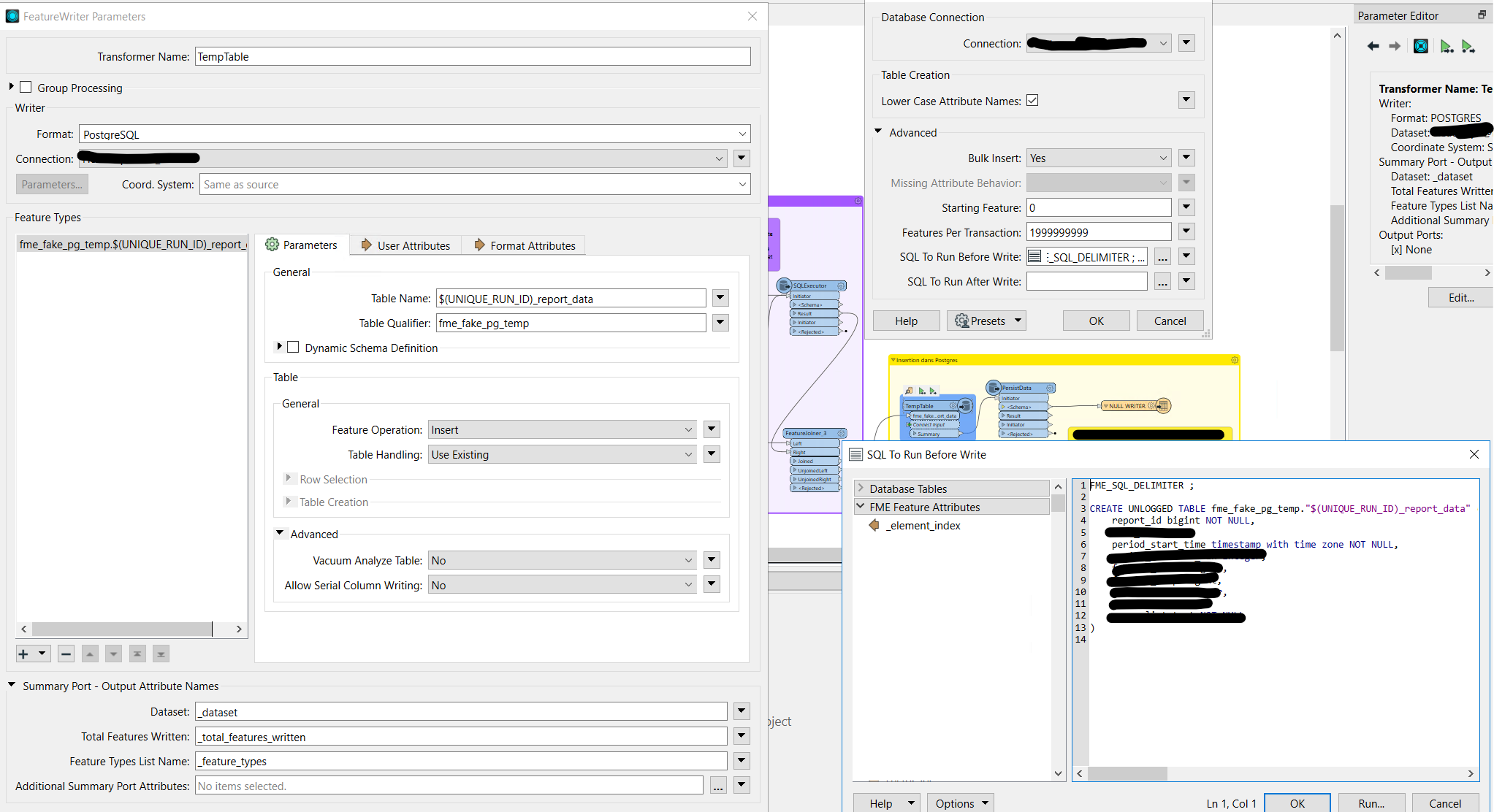
Then you just just create a Postgres writer that writes to the schema fme_fake_pg_temp, to the table $(UNIQUE_RUN_ID)_dataset_full_data, and then add the table creation, data copy between tables and table dropping code in the before and after hooks.
INSERT INTO dataset_reports (report_name_a, report_name_b) ( SELECT DISTINCT report_name_a, report_name_b FROM fme_fake_pg_temp."$(UNIQUE_RUN_ID)_dataset_full_data" ) ON CONFLICT (report_name_a, report_name_b) DO NOTHING ;
INSERT INTO "$(POSTGRES_INSERTION_SCHEMA)".dataset_report_data (...) ( SELECT ... FROM fme_fake_pg_temp."$(UNIQUE_RUN_ID)_dataset_full_data" ) ON CONFLICT (report_id, line_timestamp) DO NOTHING ;
DROP TABLE fme_fake_pg_temp."$(UNIQUE_RUN_ID)_dataset_full_data"
It's as robust as I've managed to make this, and I haven't managed to get around the very worrying side-effect where if the run after write hooks fail, the insertion is still considered to be successful. It's still the best solution I've managed to come up with so far regarding the use of temporary tables for bulk data insertion with conflict handling using real FME writers (instead of doing this in Python or something), so I figured I'd write it here. Not ideal, but at least it works.
EDIT (2023-07-18): I've realized that, if the use of real temporary tables isn,t a concern anymore, it's probably best to get rid of the Writer[Postgres] entirely and instead do the unlogged table creation and feature insertion in a FeatureWriter, and then running the "After insertion" SQL in an SQLExecutor. This means you don't risk running into the problem of data persistance errors going unnoticed, and you don't have to repeat the temporary table name in your SQLExecutor query because you can just use @Value(_feature_types{0}.name) from the FeatureWriter Summary output port.
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
These wouldn't do. I already have data I need to write (not read or determine the schema of, so something like SQLCreator or SchemaScanner wouldn't work), and SQLExecutor can't take rows in or out of your databaase, so it wouldn't be useful for that either. A Writer or a FeatureWriter would normally be all I need, but it's the temporary table part that's the issue. Specifically, that FME won't recognize how the table exists because it's temporary, and refuses to insert as a result.
Ok, so I've accepted that this isn't currently possible under FME 2022 or 2023, so I've had to make do with something else.
The use of temporary tables in PostgreSQL would mean that the tables are not logged to the WAL, are deleted after insertion and don't have any risk of collision if multiple instances of a script try creating the same table at the same time.
The first two, you can achieve with an unlogged table and a DROP TABLE in the "After SQL" hook. The third one is trickier, since there's not really any kind of "unique run ID" that I could find in FME documentation, so I've taken to creating my own by imitating TempPathnameCreator. This has to be done as a scripted user parameter, because reading this from attributes makes things even more needlessly complicated.
# User parameter: UNIQUE_RUN_ID
# Configuring a logger to catch scripted parameter errors import logging logging.basicConfig(filename=r'D:\FME\fme_param_log.log', encoding='utf-8', level=logging.DEBUG, force=True)
#print(unique_run_id) return unique_run_id except: logging.exception("Error in parameter UNIQUE_RUN_ID") raise return
Furthermore, we need a database schema to store these temporary tables, where users are allowed to create tables but not interfere with the tables of other users, and still be able to delete them:
CREATE SCHEMA IF NOT EXISTS fme_fake_pg_temp AUTHORIZATION postgres;
GRANT CREATE ON SCHEMA fme_fake_pg_temp TO PUBLIC;
COMMENT ON SCHEMA fme_fake_pg_temp IS 'PUBLIC is not granted the USAGE privilieve, so users can only access the tables they own/have created.';
Then you just just create a Postgres writer that writes to the schema fme_fake_pg_temp, to the table $(UNIQUE_RUN_ID)_dataset_full_data, and then add the table creation, data copy between tables and table dropping code in the before and after hooks.
INSERT INTO dataset_reports (report_name_a, report_name_b) ( SELECT DISTINCT report_name_a, report_name_b FROM fme_fake_pg_temp."$(UNIQUE_RUN_ID)_dataset_full_data" ) ON CONFLICT (report_name_a, report_name_b) DO NOTHING ;
INSERT INTO "$(POSTGRES_INSERTION_SCHEMA)".dataset_report_data (...) ( SELECT ... FROM fme_fake_pg_temp."$(UNIQUE_RUN_ID)_dataset_full_data" ) ON CONFLICT (report_id, line_timestamp) DO NOTHING ;
DROP TABLE fme_fake_pg_temp."$(UNIQUE_RUN_ID)_dataset_full_data"
It's as robust as I've managed to make this, and I haven't managed to get around the very worrying side-effect where if the run after write hooks fail, the insertion is still considered to be successful. It's still the best solution I've managed to come up with so far regarding the use of temporary tables for bulk data insertion with conflict handling using real FME writers (instead of doing this in Python or something), so I figured I'd write it here. Not ideal, but at least it works.
EDIT (2023-07-18): I've realized that, if the use of real temporary tables isn,t a concern anymore, it's probably best to get rid of the Writer[Postgres] entirely and instead do the unlogged table creation and feature insertion in a FeatureWriter, and then running the "After insertion" SQL in an SQLExecutor. This means you don't risk running into the problem of data persistance errors going unnoticed, and you don't have to repeat the temporary table name in your SQLExecutor query because you can just use @Value(_feature_types{0}.name) from the FeatureWriter Summary output port.
Thanks for this helpful tutorial on how to create and write to a temporary table in PostgreSQL. I learned a lot from your clear and concise explanation and examples. I have a question though: how can I access the temporary table from another session or transaction? Is there a way to make it persistent or shareable?
Here is sharing some Data Modelingmay be its helpful to you.
Thanks for this helpful tutorial on how to create and write to a temporary table in PostgreSQL. I learned a lot from your clear and concise explanation and examples. I have a question though: how can I access the temporary table from another session or transaction? Is there a way to make it persistent or shareable?
Here is sharing some Data Modelingmay be its helpful to you.
Real temporary tables in PostgreSQL are session-scoped, so you can access a temporary table you've created from two transactions so long as you do it without closing/changing your connection. Unfortunately, FME has various limitations that make these pretty much impossible to use. The accepted answer I've posted last week works around that by using unlogged tables with some generated names, and it's definitely a hacky workaround, but I wouldn't be able to (reasonably quickly) insert 100k+ rows in such a large (hundreds of millions of rows) table while doing collision checks if I was leaving it up to FME to do the insertion, I'm copying the data over to the Postgres server and leaving it up to the DB to run the insertion proper.
These fake temporary tables are still normal tables, so you could share them between transformers. Making them persistent seems somewhat against the point of having the table be temporary in the first place, though. I'm using mine to move data to the actual persistant tables before deleting the temporary one, I wouldn't really see much of a benefit in just persisting a bunch of temporary tables with half-gibberish names around.
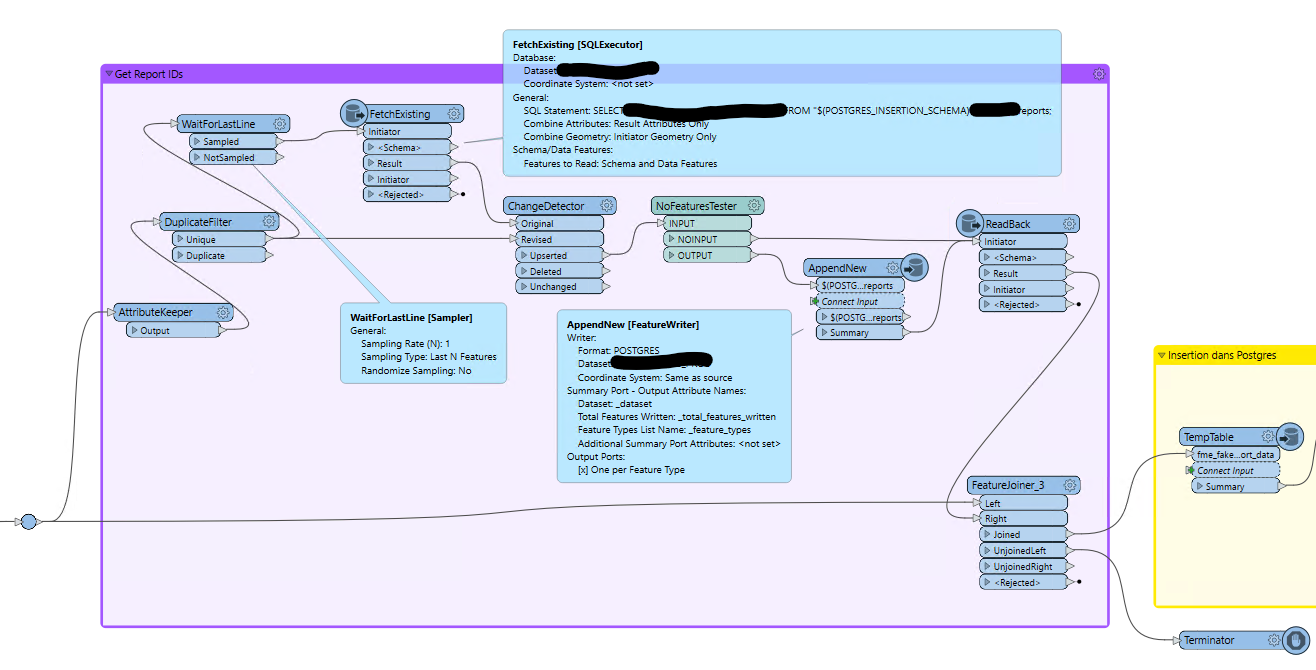
In fact, for clarity’s sake, here’s the full configuration I’m using (yellow box).
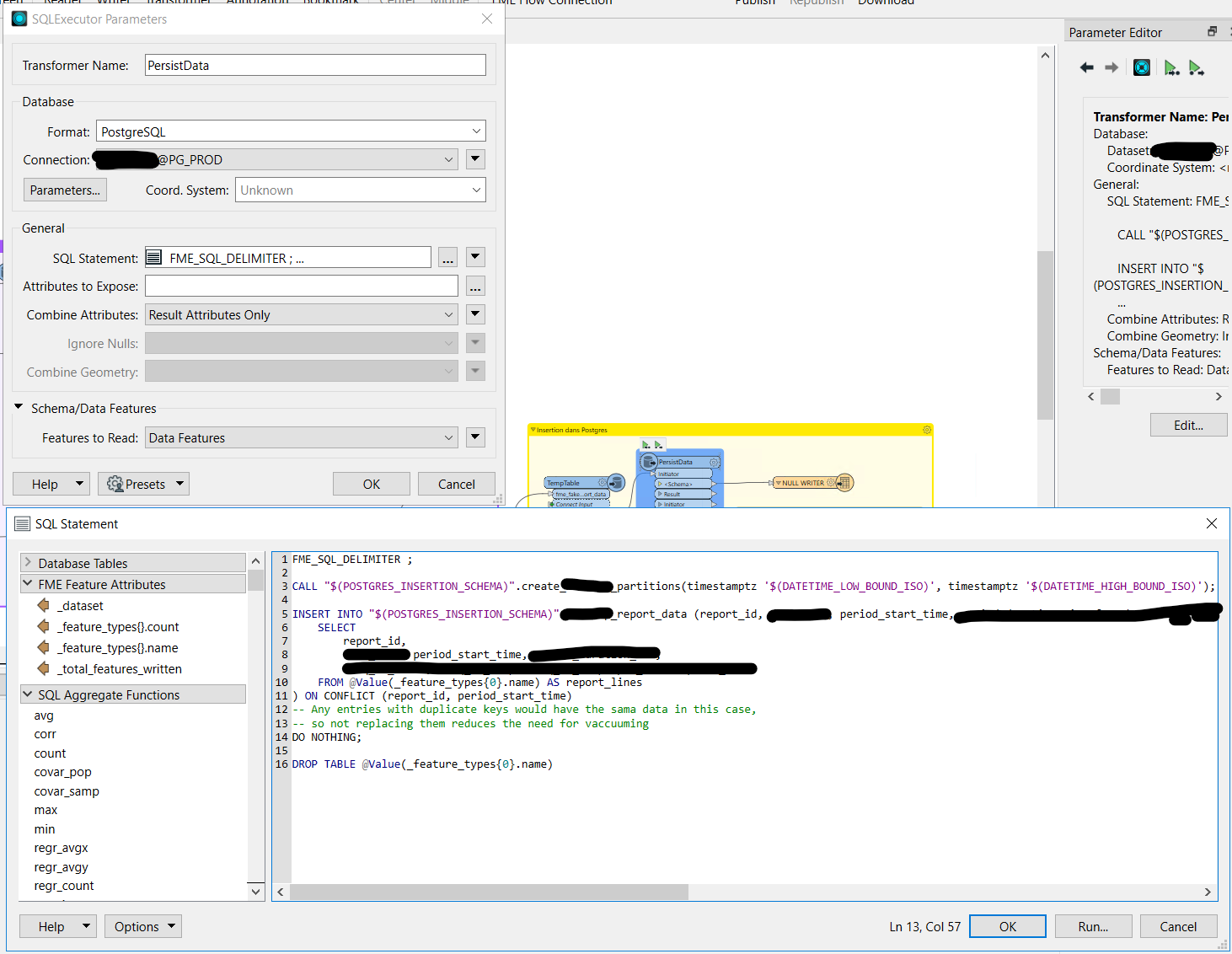
EDIT (2023-07-18): I've realized that, if the use of real temporary tables isn,t a concern anymore, it's probably best to get rid of the Writer[Postgres] entirely and instead do the unlogged table creation and feature insertion in a FeatureWriter, and then running the "After insertion" SQL in an SQLExecutor. This means you don't risk running into the problem of data persistance errors going unnoticed, and you don't have to repeat the temporary table name in your SQLExecutor query because you can just use @Value(_feature_types{0}.name) from the FeatureWriter Summary output port.
This is the SQLExecutor design I mentionned there. It has proven very reliable these past 8 months and only requires occasional cleanup of the fake temporary tables in the rare cases where insertion fails due to things like deadlocks or partitionning errors. The UNIQUE_RUN_ID parameter and fme_fake_pg_temp schema are created just like shown in that other comment as well.
The NULL WRITER is just a null writer; it always recieves three schema features (two if you don’t need to create partitions) and records them nowhere, just so I can say the flow has a definite begining and end.
Given the above situation, the text columns from the "report name" have been put into a separate "dataset_reports" table" (~60k rows); with the timestamp and actual data being stored separately (with a foreign index) in their own heavily partitionned "dataset_reports_data" (~800M rows) table. In order to insert data in that table, I need to upsert dataset_reports with all the unique report names in my feature set in a first pass, then get the FK value for all these reports and then I can insert the actual data in "dataset_reports_data".
Also for the record, I ended up doing the foreign key resolution in FME, after validating that the time cost of doing that was actually acceptably short. ReadBack is identical to FetchExisting, but it selects the report_id primary key from "dataset_reports" that "dataset_reports_data" needs to use as part of its foreign key.