
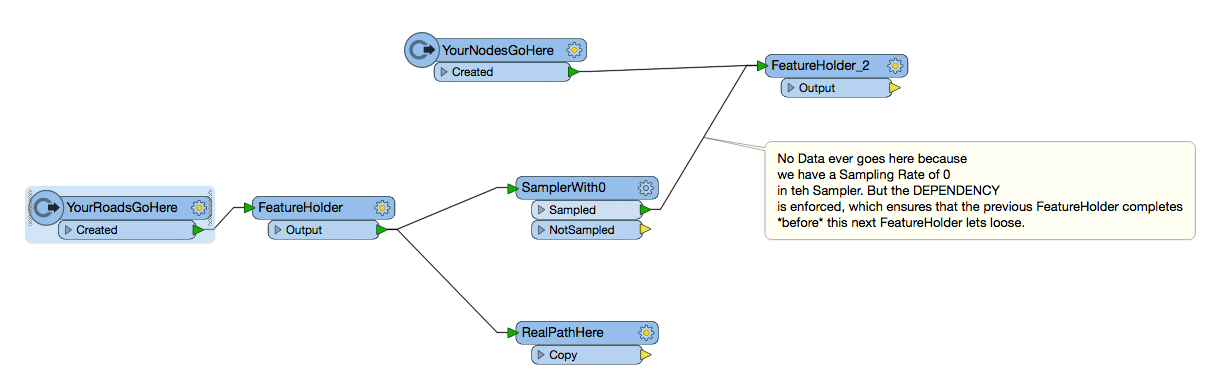
I have a reader that has two sets of variables roads and nodes. I want it to go through and process all the roads and run that through the transformers and save to the database before the nodes part of the file gets read and processed. Need some of the road info to help process the nodes. Is their a way to ensure that the roads are completed before the nodes start to process in a single workbench or do I need to break it up and use a FMEserverworkspacerunner. If possible i would like to avoid this and keep everything on one workspace.

Question
Holding an entire workbench
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.







Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.