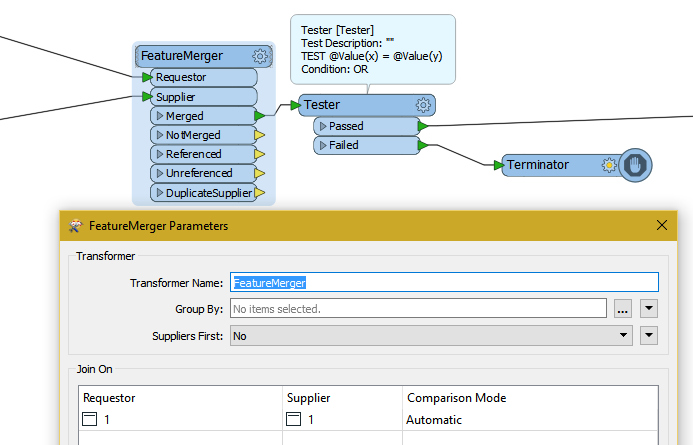
I have a SQLCreator that returns x number of features, and FeatureMerger that returns y number of features. I then want to compare the two counts (Does x = y?) and if that is false, then I want to do certain things, including generating a string (for logging or notification) that is something like "Table1 has x features and Table2 has y features."
I can get the respective counts (StatisticsCalculator), and I can compare the counts (Tester) and I can (incorrectly) generate the string (StringConcatenator). My problem is more about storing/saving values, and regulating their population and use.
For example, two counts comes in as two features, so I get two comparisons, and two strings:
- Table1 has x features and Table2 has <null> features.
- Table1 has <null> features and Table2 has y features.
FeatureHolder seems only to delay the inevitable. What am I not fundamentally understanding about feature processing that is making this harder than it should be?
Thank you very much!