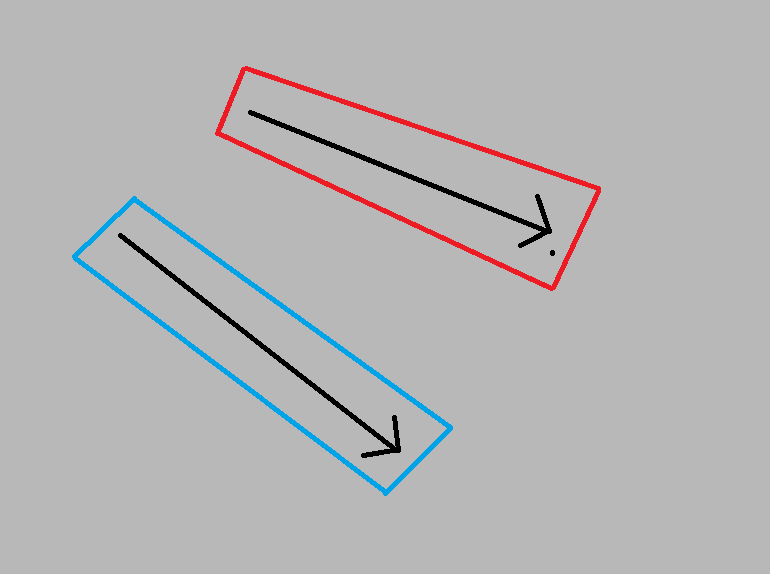
I have a collection of lines and I need to first select those within X distance of each other, and then merge into one feature if the headings are the same (within a specified threshold) and they are of the same type (specified attribute).
The result will be one line representing a grouping of features that are of the same type and heading in roughly the same direction.
Does anyone have any ideas on how to approach this?
So in the image below, step one would be to find the groupings of lines within x distance and heading in the same direction.

After this selection I want to group them into one feature based on a specific attribute. in the image below, these lines are grouped according to a specified attribute.

The end result would be this, one line representing all of the merged lines heading in the same direction and grouped by a specific attribute.