
Lets say I'm reading in several shape files. They are called "Birds", "Dogs" etc.The 'fme_feature_type' has the same name. There is an Attribute with the name "Race" (containing e.g. 'Finch', 'Crow', 'Falcon' ...)
I need a csv file with the field names set to the feature type and the races beneath it.
It should look like this:
Birds Dogs Fish
Finch labradoodle ............
Crow dachshund ........
Falcon pit bull terrier ....
much obliged




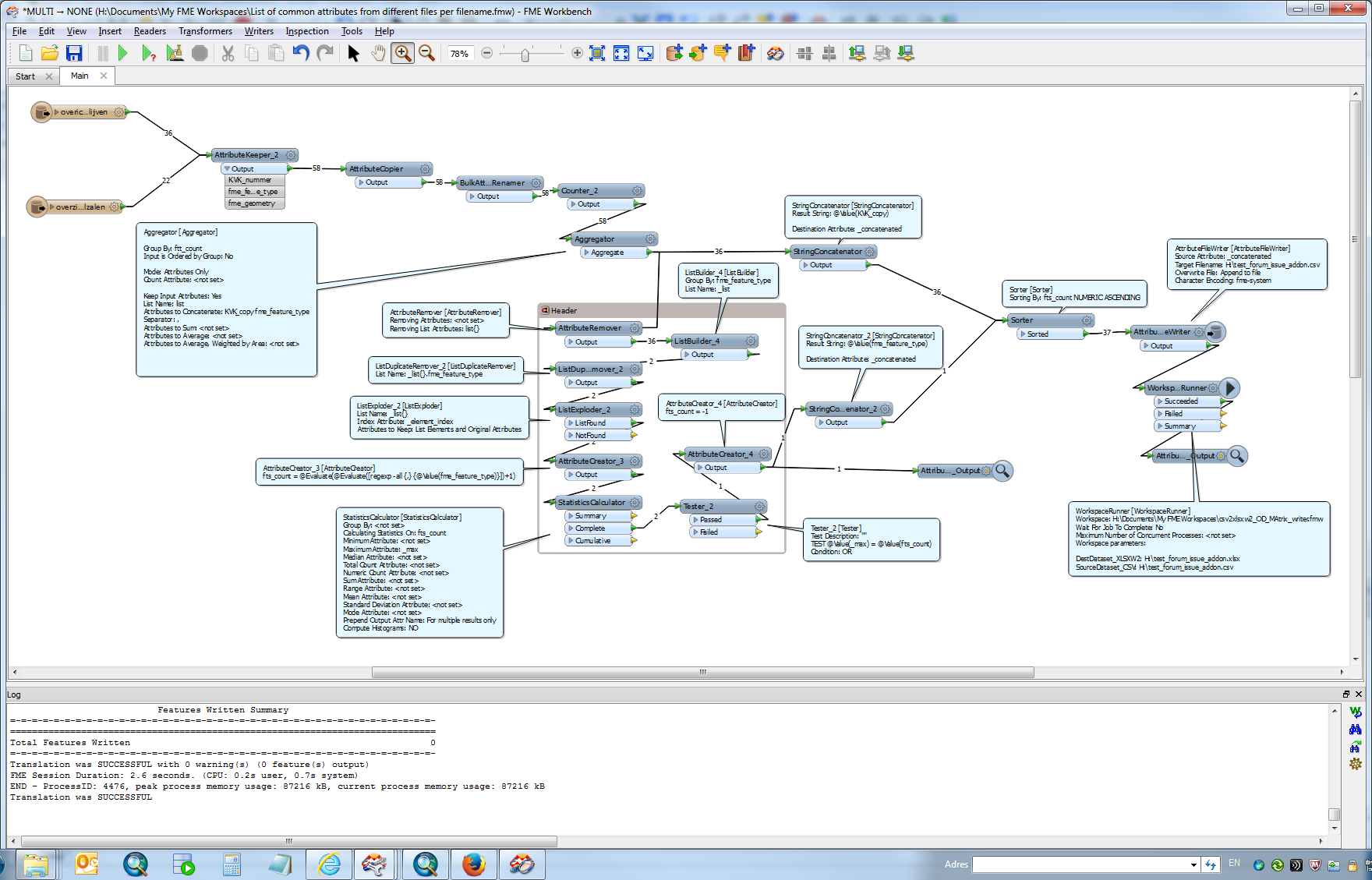
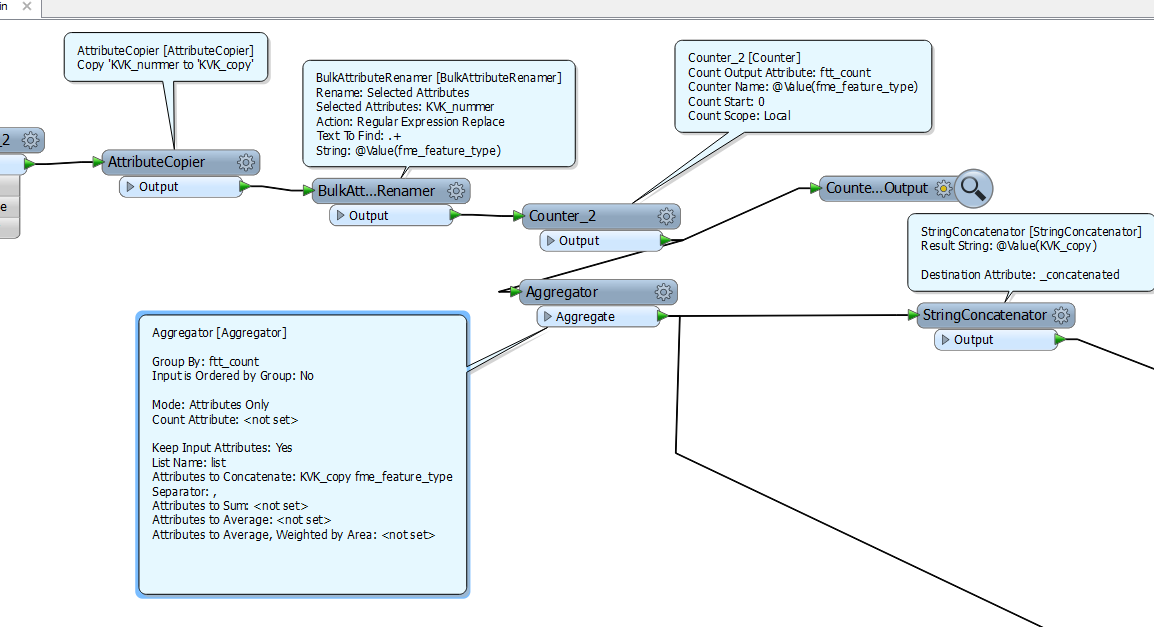
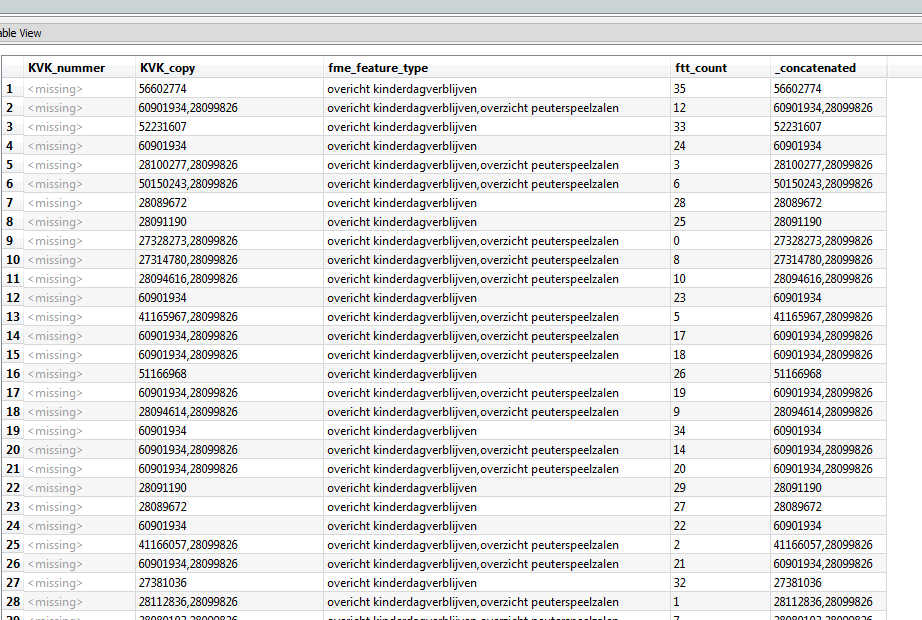 in you rcase KVK_copy would be Race_copy, fme_feature_type would hold filenames (the Names).
in you rcase KVK_copy would be Race_copy, fme_feature_type would hold filenames (the Names).