
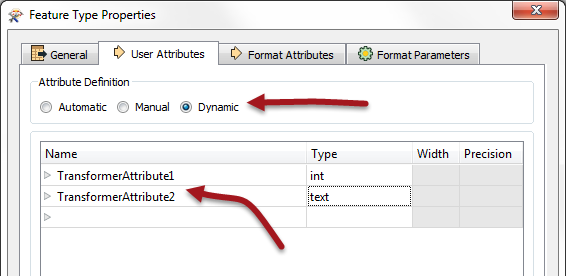
I am trying to build a workbench that performs certain checks irrespectively of the Input data. That means that it must accept data with different data types (.shp, .mdb...) and schemes (e.g. different attribute names and types). As far as I know, a generic dynamic reader is what I need. So I inserted one and tested it. Although this reader reads the (spatial) data and shows its polygons in the inspector, the attributes are lost. Instead of the original attributes, there is only one row in the table with the header <no schema>. In the feature information part of the inspector, however, the attributes are still listed. Since I want to write a log file including all the errors found by the checker, the attributes are important. What do I need to do, so that I can access the attributes of the generic dynamic reader?
Best regards
André









")
