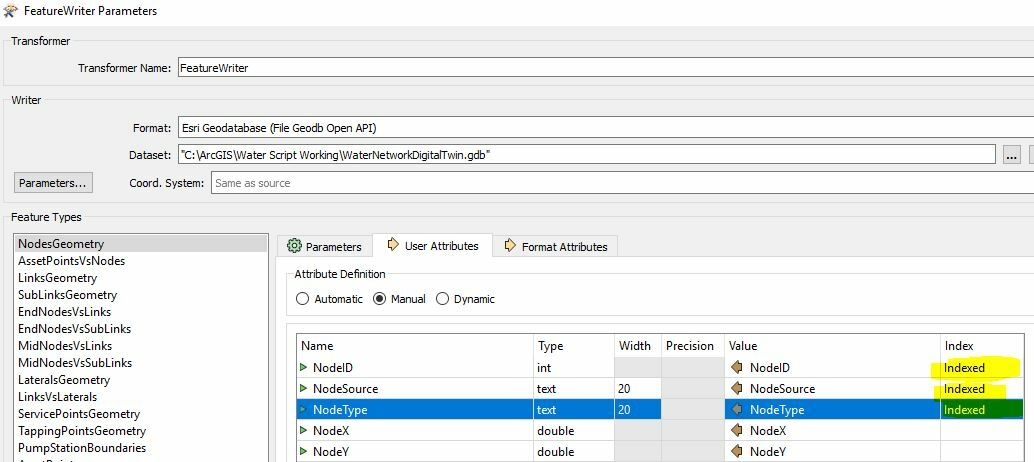
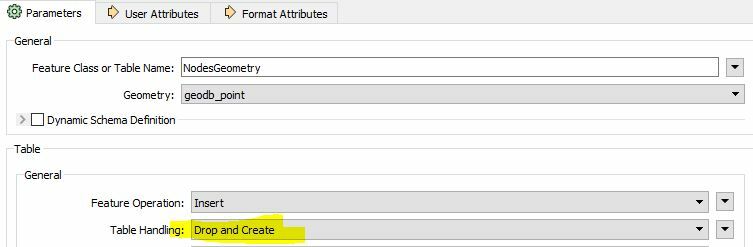
So, I hope I have this right. As far as I can tell, the default behaviour for FeatureWriter is to create any field indices during the CREATE TABLE or ALTER TABLE stage by issuing commands like CREATE INDEX before any features get written.
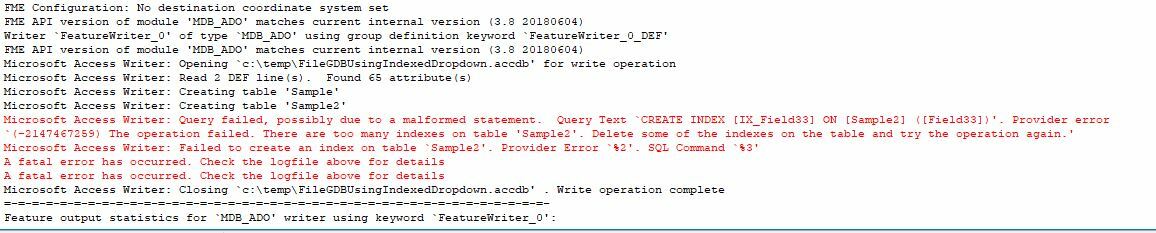
However, this would be against normal mass data append default convention? Writing bulk data against indexed tables can be very slow and in most cases best performance is to create the indices after the data is written. For instance, my FGDB FeatureWriter takes 2 hours to write my current project with the relevant fields set for indexing because every single feature written triggers a resorting of the indices, versus 15 minutes if I leave the field indexing options off.
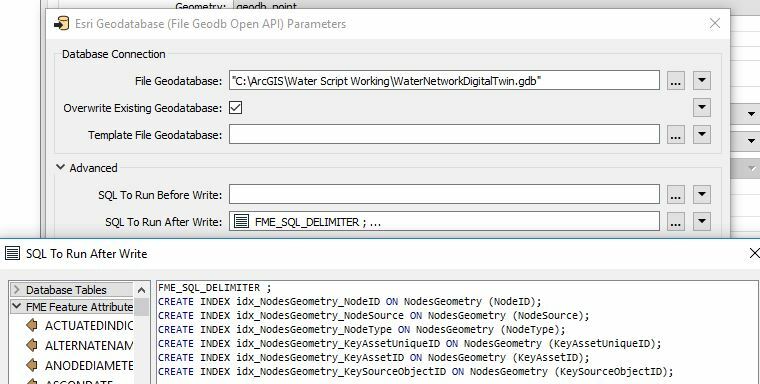
The best workaround I can come up with at the moment is to instead do post writing index creation by manually writing out the the "CREATE INDEX..." statements in the "SQL to run after Write" parameter, but can anyone think of other workarounds or why indices would generally need to be created before writing the data out (excepting cases where some index sensitive SQL statements may need to run in the "SQL to run before Write" parameter, but I'm guessing in general use cases most workflows this Parameter would be blank?)