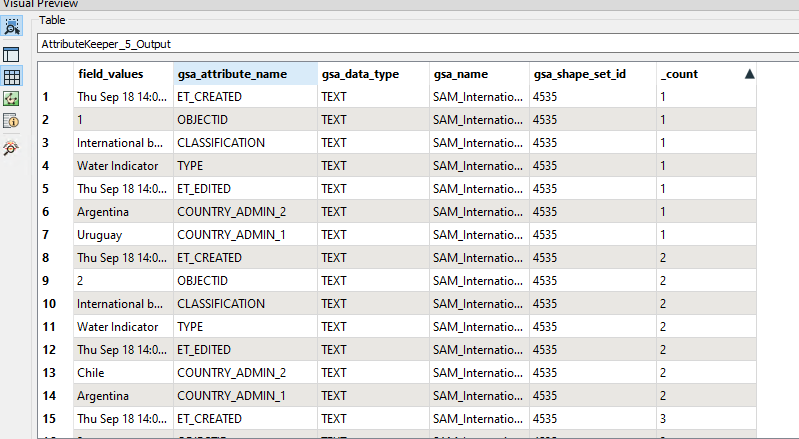
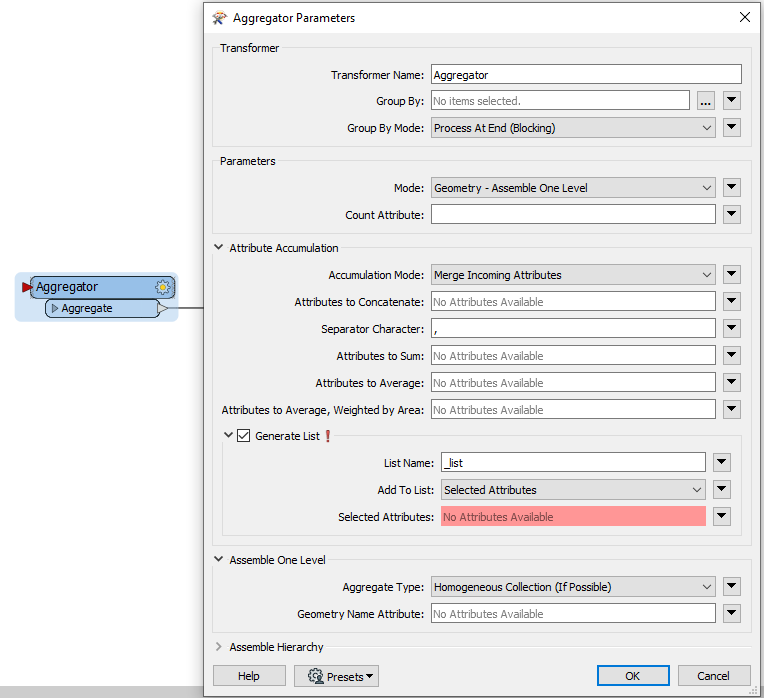
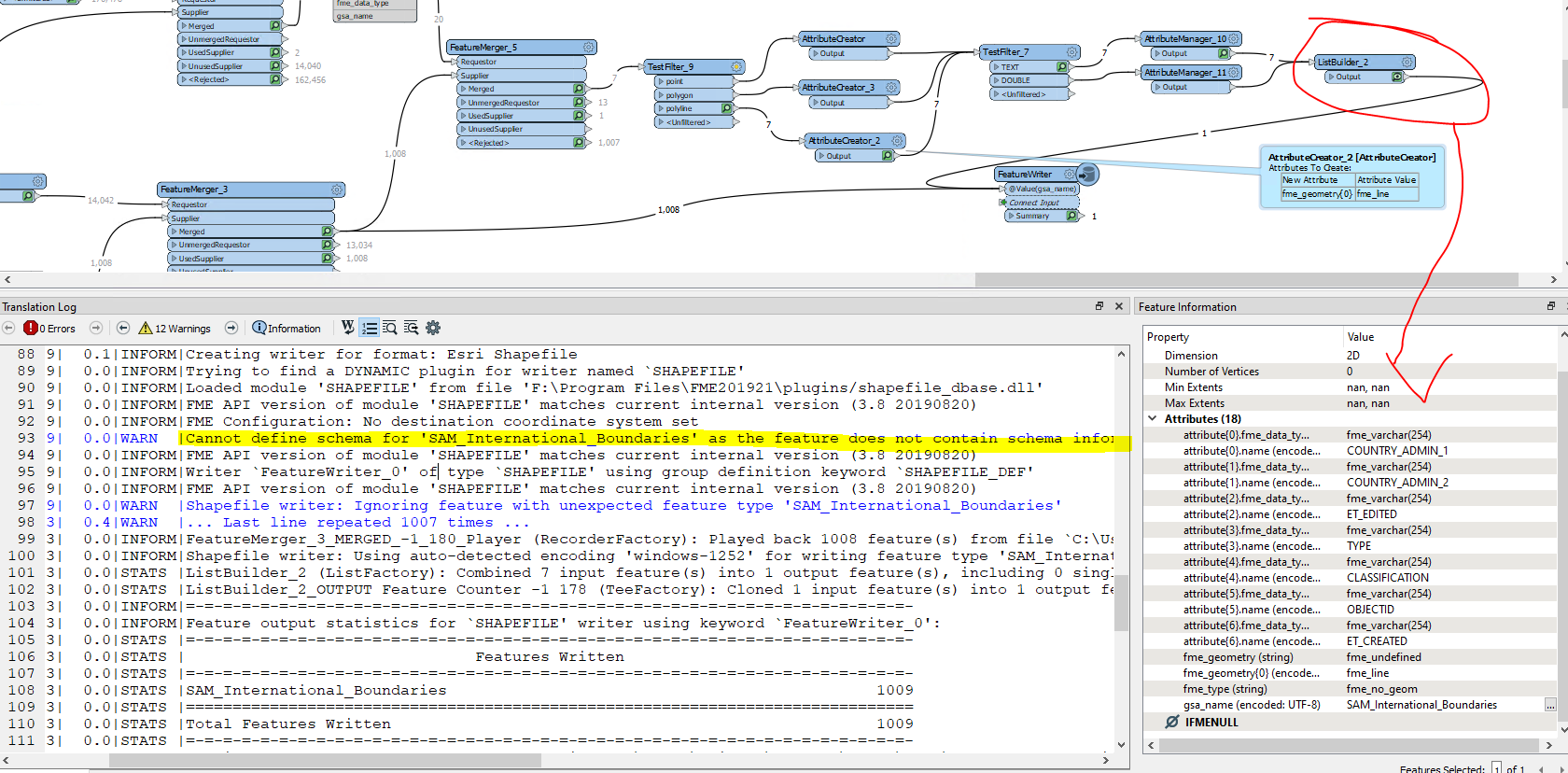
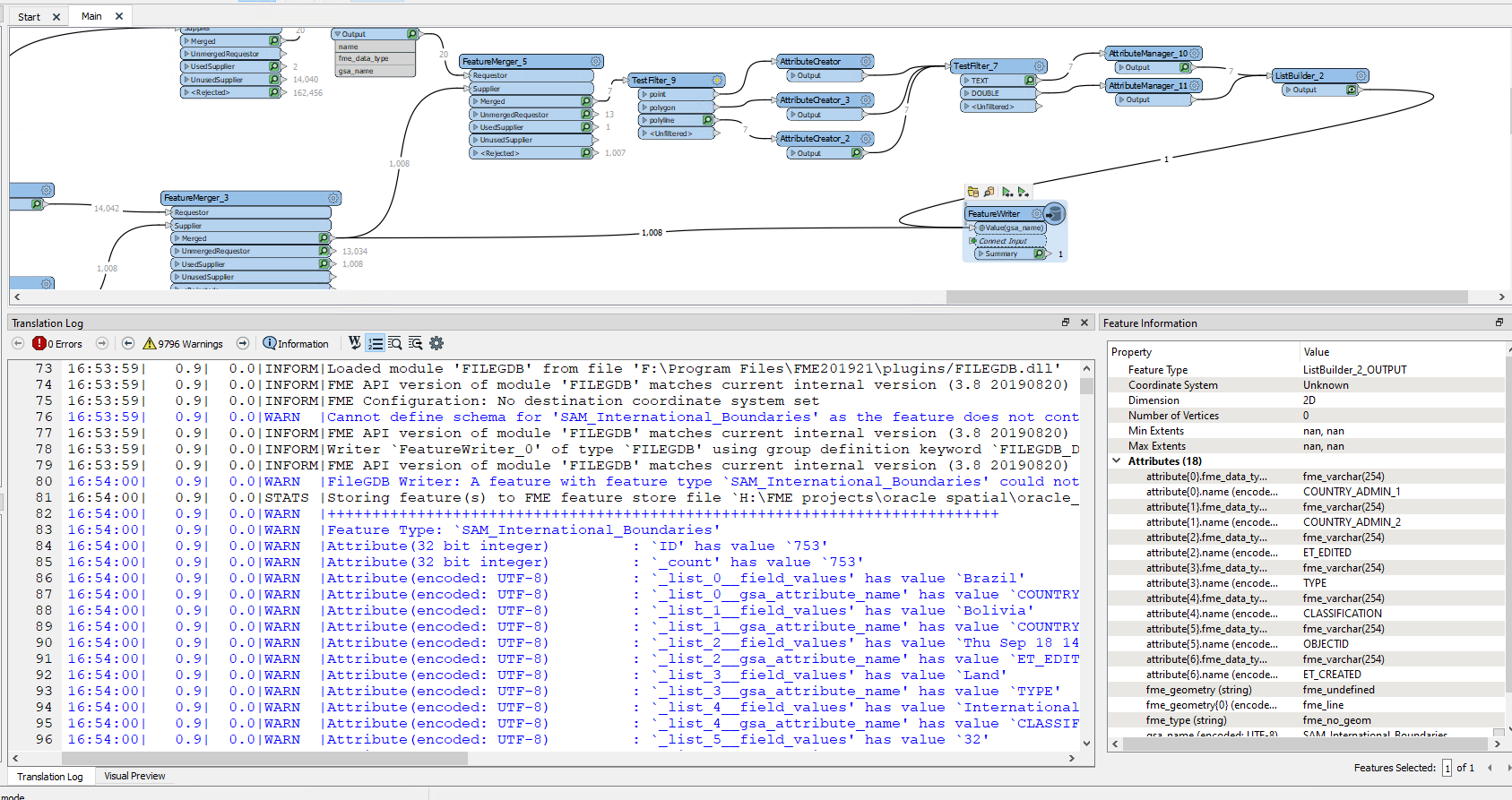
The schema feature has to arrive in the writer before any data features, if you intend to configure the destination schema dynamically and use the attribute{} list as the schema definition.
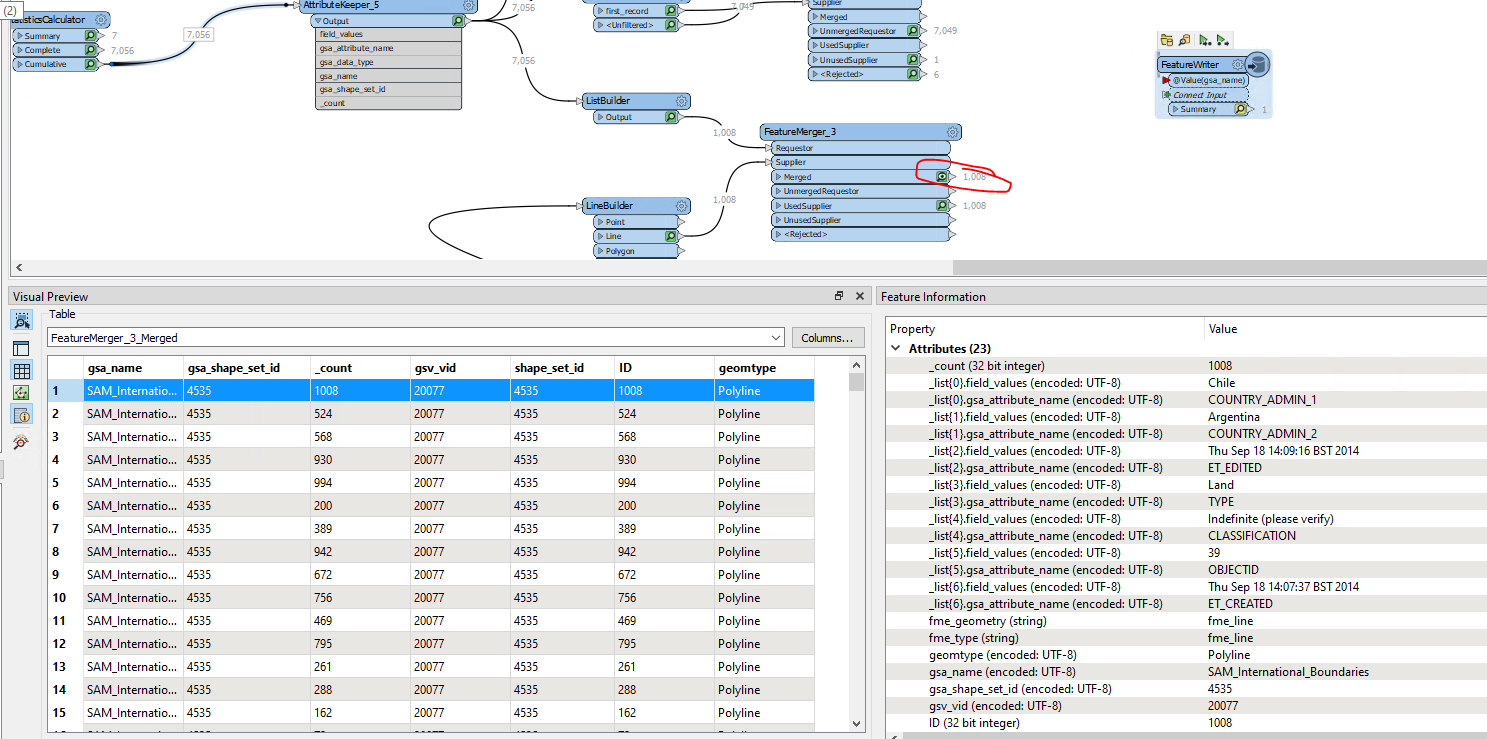
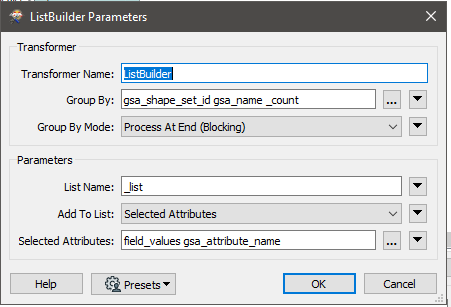
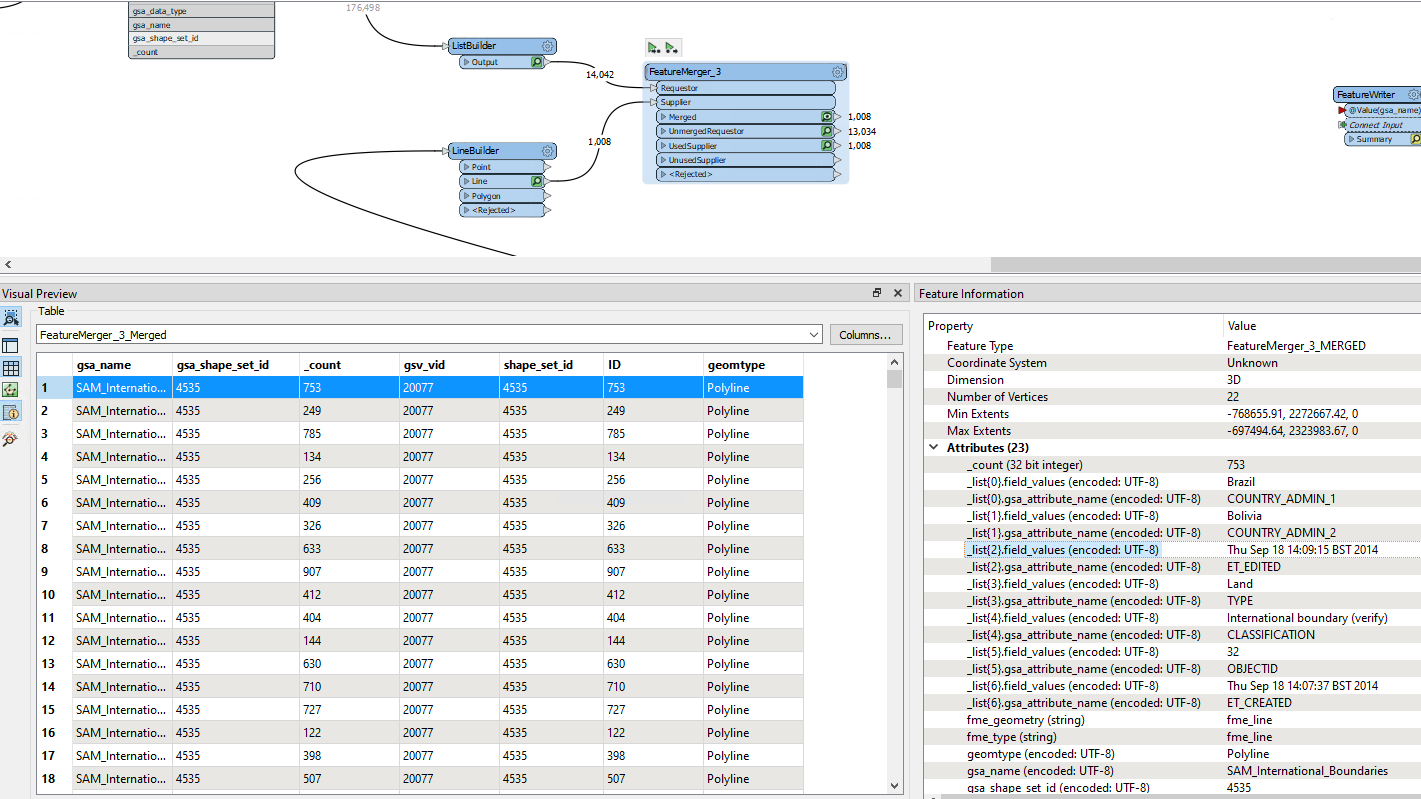
In your workflow, there are blocking transformers (FeatureMerger and ListBuilder) on the data flow for creating the schema feature, so the schema feature would arrive after the data features. Also a schema feature should have two special attributes - fme_feature_type_name containing the schema definition name and fme_schema_handling containing "schema_only".
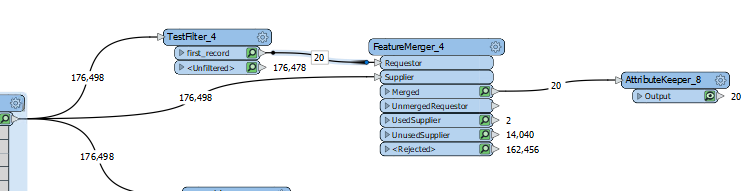
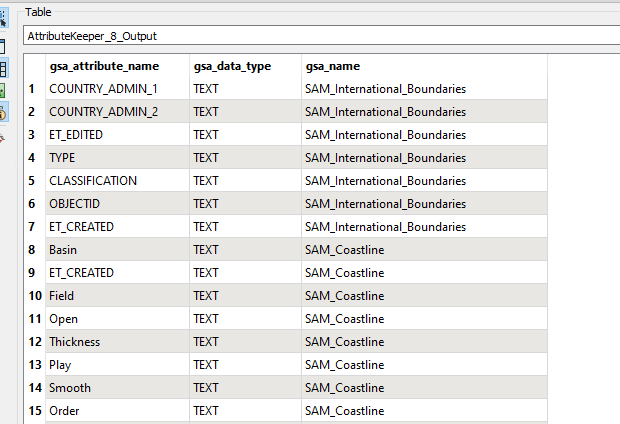
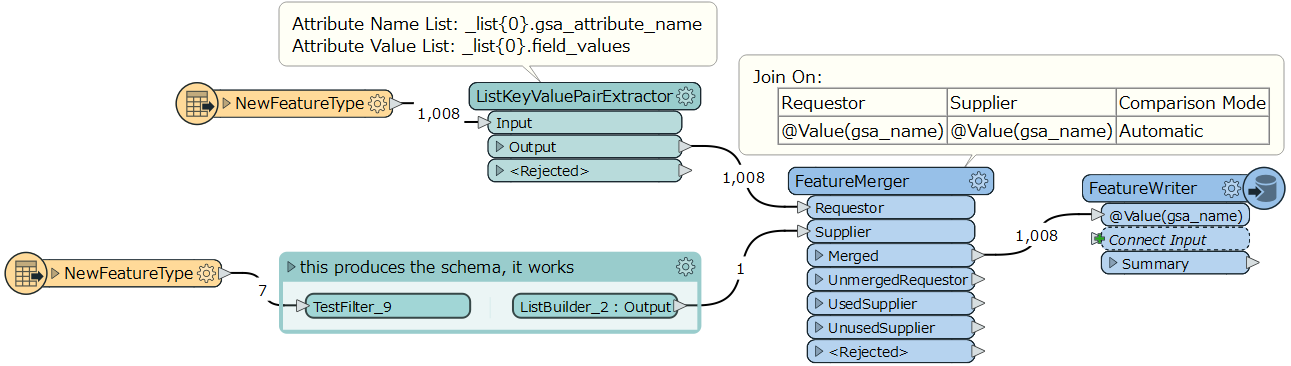
A possible workaround is, unconditionally merge the schema definition (i.e. the attribute{} list and the fme_geometry{} list) to every data feature using a FeatureMerger before writing. I think it would be easier than configuring a schema feature properly and controlling the order of features.
In fact, it's an application of the traditional method "Destination Schema is Derived from a List in the First Feature", which is still available even though it's not documented anywhere now. The modern method "Destination Schema is Derived from a Schema Feature" is a variant of the traditional one.