Hi
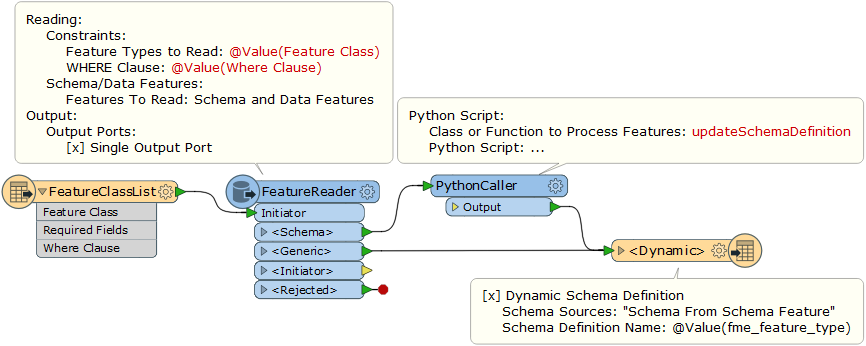
I have an excel with list of feature classes to read, attribute fields (comma delimited) and where clause(ex: myfield = 'Yes' and MyField2='abc')
Reading excel, passing to feature reader with where clause is fine, works ok
My issue, is how do I -
> dynamically write selected features from feature reader to writer
> with only attribute fields required (coming from excel in comma delimited texts)
[ if not possible at least write all read attributes to write, again shud be dynamic as each input feature class\\att fields will be different.]
> pass feature class names built prior to feature reader
A work around solution and an example will really help solve my problem.
Tried to search similar example, couldn't figure out.
Really appreciate your help
Thank you all