I'm having a hard time even coming up with a title for this problem that I'm seeking help on. But I'll summarize and provide context as much as I can.
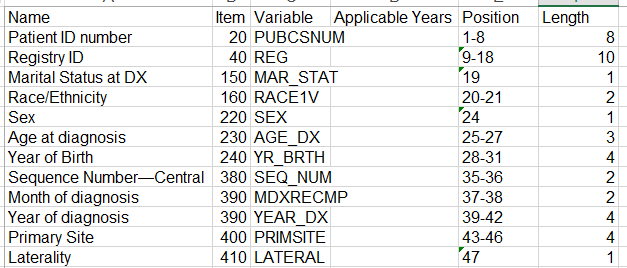
We are trying to parse publicly available medical data. This data is provided as a concatentation of multipe substrings (ex: 100 or more fields) in one long string. An accompanying document describes the start and end position of each substring that defines the value of a field. I was able to mock up a quick workflow to dynamically supply a single row Excel or CSV file with this data (see excerpt below that I used as a proof of concept) and then feed in the long string text data file:

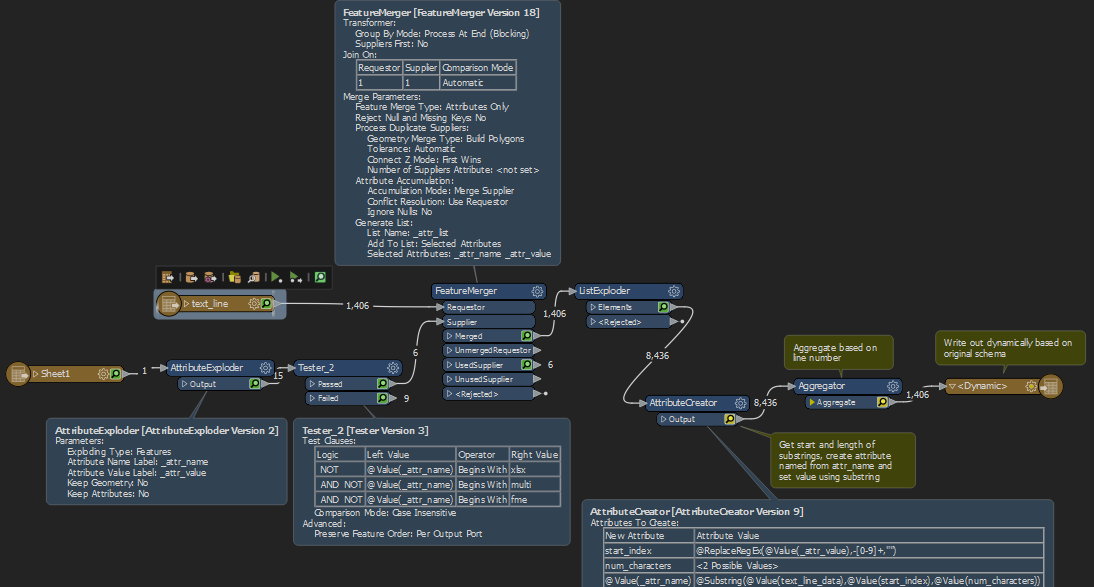
The workspace reads the above and uses an AttributeExploder to "transpose" this table. I then clean out unwanted features and do some calculations to create an appropriate StartIndex and EndIndex (which I use later to extract the substrings). After reading each line in the text file, I then use a FeatureMerger to stitch this together with the above:
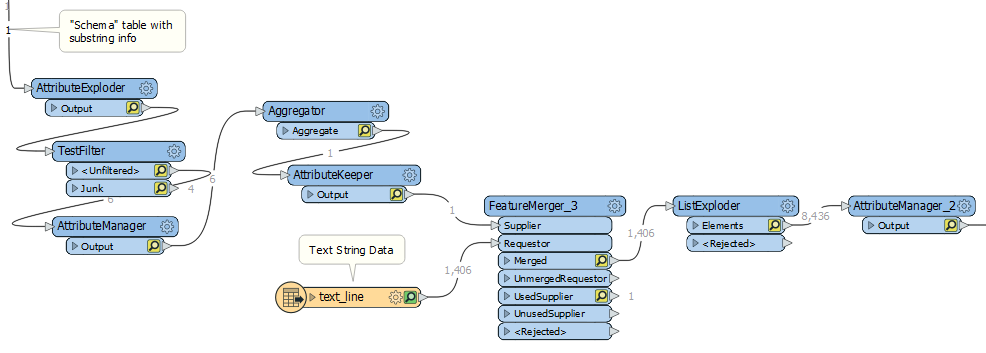
With some formulas in the last AttributeManager in the above, I then extract the needed substrings. This gets me very close to what I need, but not exactly. Since these datasets can have hundreds of fields, my goal is to make this as generic as possible (I don't want to define the exact attribute names in an AttributeManager). The user would simply need to get the "substring mapping" data from the supporting documentation and enter it into Excel (we'll call this the "Schema Table") and use a workspace to reformat the data. The problem is that I'm now ending up with data where some of the rows actually define the fields (ex: highlighted 6 features are really one feature with 6 attributes whose name is the value of "_attr_name") Notice how these repeat every 6 features in this example:
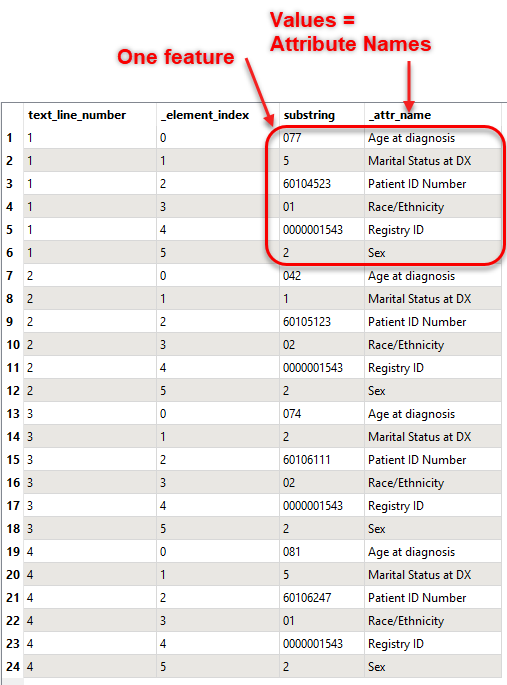
I am looking for help with restructuring this so I can get the data formatted dynamically, regardless of number of attributes etc. Any help would be greatly appreciated. I suspect this cannot be done directly with Transfoermers (I hope that is not the case!) so if Python is needed to solve this, I'm open to that suggestion as well. It's almost like I need something to organize the features in groups of "X" (6 in this example) based on the number of attributes in the Schema table, then transpose each group. Thanks.